
Postman API to praktyczne środowisko do pracy z interfejsami backendowymi: pozwala wysyłać żądania, sprawdzać odpowiedzi, porządkować endpointy w kolekcjach i zamieniać ręczne testy w powtarzalny proces. W praktyce przydaje się programiście backendu, testerowi, frontendowcowi integrującemu się z usługą i każdemu, kto musi szybko ustalić, czy dany endpoint działa tak, jak powinien. Pokażę, jak sensownie zacząć, jak tworzyć dokumentację, jak pisać testy i kiedy takie podejście naprawdę oszczędza czas.
Najkrócej: Postman porządkuje testy, dokumentację i współpracę wokół API
- To nie tylko klient HTTP, ale też miejsce na kolekcje, środowiska, zmienne, testy i dokumentację.
- Największą wartość daje wtedy, gdy pracujesz na kolekcjach i zmiennych, a nie na twardo wpisanych danych.
- Dokumentacja ma sens tylko wtedy, gdy jest powiązana z realnymi requestami i przykładami odpowiedzi.
- Automatyzację warto zaczynać od prostych asercji: statusu, wymaganych pól i poprawnej struktury danych.
- Do terminala i CI lepiej użyć narzędzi do uruchamiania kolekcji niż ręcznego klikania.
- To narzędzie wspiera pracę z API, ale nie zastępuje całej strategii testów backendu.
Czym jest Postman i gdzie najlepiej sprawdza się w pracy z API
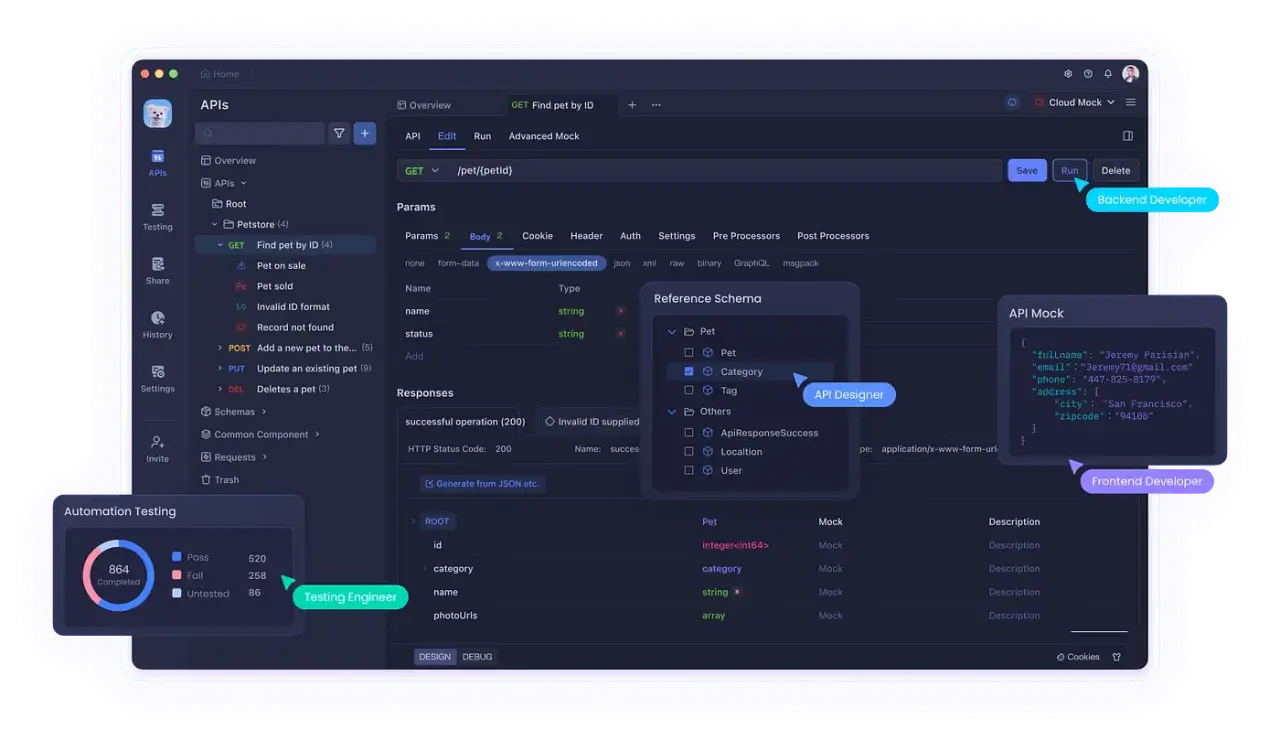
Najprościej ujmując, Postman porządkuje cały cykl pracy nad endpointem: od pierwszego requestu, przez sprawdzanie nagłówków i ciała odpowiedzi, po zapisanie scenariuszy w kolekcji. Ja traktuję go raczej jako operacyjne centrum API niż zwykły klient HTTP, bo w jednym miejscu trzymasz też środowiska, zmienne, testy i dokumentację.
- Kolekcje grupują requesty według modułu, procesu albo obszaru biznesowego.
- Środowiska pozwalają przełączać np. lokalny, stagingowy i produkcyjny adres bez przepisywania żądań.
- Zmienne trzymają wartości takie jak adres bazowy, token czy identyfikator użytkownika.
- Testy sprawdzają, czy odpowiedź ma właściwy status, strukturę i dane.
- Dokumentacja pokazuje innym, jak korzystać z endpointów bez ręcznego tłumaczenia każdego requestu.
Jak zbudować sensowny workflow od pierwszego requestu do kolekcji
Najpierw rozdzielam to, co stałe, od tego, co zmienia się między środowiskami. Adres serwera, token i kilka identyfikatorów lądują w zmiennych, bo hardkodowanie wartości w każdym requestcie jest prostą drogą do chaosu. Jeśli ktoś po tygodniu ma wrócić do projektu, powinien zrozumieć strukturę bez zgadywania, gdzie ukrył się staging, a gdzie produkcja.
Używaj środowisk zamiast duplikować requesty
W praktyce najczęściej utrzymuję osobne środowiska dla lokalnego developmentu, testów integracyjnych i produkcji. Dzięki temu ten sam request trafia w inny adres, ale logika pozostaje identyczna. To ważne, bo kopie tych samych żądań szybko zaczynają się rozjeżdżać, a wtedy nie wiadomo już, które ustawienie jest aktualne, a które zostało po staremu.
Porządkuj kolekcje według procesu, nie według przypadku
Zamiast wrzucać wszystko do jednego worka, wolę układ oparty na procesach: użytkownicy, zamówienia, płatności, autoryzacja, webhooki. W takim układzie kolekcja staje się mapą API, a nie zbiorem przypadkowych kliknięć. Dla zespołu to realna oszczędność czasu, bo nowa osoba może od razu uruchomić logiczny scenariusz, zamiast czytać każdy request po kolei.
- Ustal środowiska i nazwij je jednoznacznie.
- Przenieś powtarzalne wartości do zmiennych.
- Dodawaj requesty do kolekcji, a nie luzem do osobnych zakładek.
- Nazywaj requesty akcją i zasobem, na przykład „Users - create” albo „Orders - get by id”.
- Dołącz przykładowe odpowiedzi, zanim kolekcja urośnie do kilku modułów.
Dobry workflow kończy się tym, że nowa osoba w zespole może uruchomić kolekcję bez zgadywania, co wpisać w każdym polu. Kiedy ten fundament działa, dokumentacja przestaje być dodatkiem, a staje się naturalnym opisem tego samego źródła prawdy.
Dokumentacja, którą z zespołem da się naprawdę utrzymać
W dokumentacji API najbardziej cenię prostotę: ma pokazywać, co endpoint przyjmuje, co zwraca i czego wymaga, a nie udowadniać, że ktoś potrafi napisać długi opis. Postman dobrze się do tego nadaje, bo dokumentacja może wyrastać bezpośrednio z kolekcji i opisywać parametry, nagłówki, body, odpowiedzi oraz przykłady. To jest ważne, bo dokument, który nie idzie za kolekcją, bardzo szybko traci wartość.
| Co opisać | Po co to robię | Najczęstszy błąd |
|---|---|---|
| Autoryzacja | Bez tego integracja często nie ruszy | Ukrywanie wymaganych nagłówków albo tokenów |
| Parametry i body | Pomagają zweryfikować walidację i wymagane pola | Brak przykładów wartości i formatów |
| Przykładowe odpowiedzi | Skracają czas wdrożenia po stronie frontendu i QA | Pokazywanie tylko jednego, idealnego wariantu |
| Kody błędów | Ułatwiają debugowanie i obsługę wyjątków | Opisywanie wyłącznie odpowiedzi 200 |
Najlepsze efekty daje dokumentacja, która nie kończy się na samym opisie pola, ale pokazuje też sens danych: wymagane wartości, zakresy, domyślne ustawienia i ograniczenia. Jeśli endpoint przyjmuje numer telefonu, dobrze jest zaznaczyć format. Jeśli zwraca status zamówienia, warto pokazać więcej niż jeden scenariusz, bo integrator i tak zapyta o przypadek odrzuconej płatności albo anulowania. Właśnie tutaj dobrze widać różnicę między dokumentacją „na papierze” a dokumentacją, z której da się pracować.
Kiedy dokumentacja jest spójna z kolekcją, naturalnym kolejnym krokiem są testy, bo wtedy przestajesz tylko opisywać API, a zaczynasz realnie sprawdzać jego zachowanie.
Testy, które wyłapują regresje zanim trafią na produkcję
W Postmanie testy pisze się po odpowiedzi serwera, czyli wtedy, gdy wiesz już, czy endpoint w ogóle zadziałał. To dobre miejsce na proste asercje: status kodu, obecność pól, strukturę odpowiedzi, poprawny typ danych albo zgodność z regułą biznesową. Ja zaczynam od małych rzeczy, bo one najczęściej wykrywają regresję szybciej niż rozbudowane scenariusze.
Co warto sprawdzać w pierwszej kolejności
- Status HTTP - czy endpoint zwraca to, czego oczekujesz w danym scenariuszu.
- Wymagane pola - czy odpowiedź nie gubi kluczowych danych, np. `id`, `status` albo `email`.
- Strukturę payloadu - czyli układ odpowiedzi, a nie tylko pojedynczą wartość.
- Błędy walidacji - szczególnie ważne przy formularzach, rejestracji i checkoutcie.
- Zależności między requestami - na przykład najpierw logowanie, potem użycie tokenu w kolejnym żądaniu.
pm.test("status 200", () => {
pm.response.to.have.status(200);
});
pm.test("odpowiedź ma id", () => {
const body = pm.response.json();
pm.expect(body.id).to.be.ok;
});W praktyce nie testuję wszystkiego tak samo. Czas odpowiedzi sprawdzam ostrożnie, bo pojedynczy pomiar bez kontekstu środowiska i obciążenia potrafi bardziej zmylić niż pomóc. Za to walidacja struktury i pól obowiązkowych daje szybki sygnał, że coś się rozjechało po stronie backendu, kontraktu albo mapowania danych. W e-commerce szczególnie pilnuję ścieżek typu koszyk - zamówienie - płatność, bo tam nawet drobna zmiana potrafi zablokować sprzedaż.
Przeczytaj również: Stos technologiczny backendu i API - Jak wybrać mądrze?
Jak uruchamiać testy poza aplikacją
Do ręcznego sprawdzania wystarcza kolekcja uruchamiana w samym Postmanie, ale gdy testy mają wejść do pipeline, warto je odpinać od klikanej aplikacji. Do tego służy Collection Runner, uruchamianie w harmonogramie, monitorowanie oraz narzędzia wiersza poleceń. Oficjalna dokumentacja pokazuje też, że skrypty potrafią przekazywać dane między requestami i budować cały przepływ testowy, a nie tylko pojedynczą asercję.
| Narzędzie | Po co je używam | Kiedy wybieram je najczęściej |
|---|---|---|
| Collection Runner | Jednorazowe lub cykliczne uruchamianie zestawu requestów | Gdy chcę szybko sprawdzić pełny scenariusz w aplikacji |
| Monitors | Planowane uruchomienia i alerty o problemach | Gdy chcę pilnować działania API po wdrożeniu |
| Postman CLI / Newman | Uruchamianie kolekcji z terminala i w CI/CD | Gdy test ma wejść do builda albo pipeline’u |
To rozróżnienie jest ważne, bo wiele osób zaczyna od ręcznego klikania i kończy na tym samym, mimo że projekt już dawno wymaga automatyzacji. Jeśli scenariusz jest krytyczny biznesowo, nie zostawiałbym go tylko w interfejsie. Lepiej mieć jeden dobry zestaw testów uruchamianych regularnie niż dziesięć nieopisanych requestów, do których nikt nie zagląda po pierwszym tygodniu.
Kiedy Postman wygrywa, a kiedy lepiej wybrać inne podejście
Postman najlepiej sprawdza się tam, gdzie potrzebujesz szybkiej diagnozy, spójnej dokumentacji i wygodnej pracy zespołowej. Do sprawdzenia endpointu, obejrzenia nagłówków, podmiany danych i zbudowania prostego scenariusza integracyjnego jest po prostu bardzo wygodny. Gdy jednak mówimy o dużym, twardym zestawie testów regresji, sam interfejs przestaje wystarczać i warto przenieść ciężar do pipeline’u albo do testów pisanych w kodzie.
| Sytuacja | Najlepszy wybór | Dlaczego |
|---|---|---|
| Szybkie sprawdzenie endpointu | Postman lub curl | Liczy się tempo i prosty podgląd odpowiedzi |
| Powtarzalny scenariusz integracyjny | Postman z kolekcją i testami | Łatwo zbudować czytelny flow requestów |
| Stała regresja w pipeline | Postman CLI, Newman albo testy w kodzie | Ważna jest automatyzacja i wynik możliwy do odczytu przez CI |
| Pełna walidacja kontraktu biznesowego | Testy backendowe lub kontraktowe | Większa kontrola nad logiką, asercjami i danymi |
Jest też ograniczenie praktyczne: przy bardzo dużych uruchomieniach wygodniej pracuje się w aplikacji desktopowej niż w przeglądarce, a niektóre rozszerzone scenariusze zależą od planu albo wybranej ścieżki uruchamiania. Dlatego ja traktuję to narzędzie jako mocny element procesu, ale nie jako jedyne rozwiązanie dla całego backendu. Dobrze działa w duecie z testami pisanymi w kodzie, bo jedno służy do szybkiego sprawdzenia i komunikacji, a drugie do głębszej kontroli jakości.
Jak nie zamienić go w zbiorowisko przypadkowych requestów
Najwięcej problemów widzę wtedy, gdy ktoś zaczyna dobrze, a potem zostawia po sobie rozproszone requesty, niespójne nazwy i zmienne z przypadkowymi wartościami. Żeby tego uniknąć, trzymam się kilku prostych zasad. Nie są efektowne, ale oszczędzają najwięcej czasu, bo porządkują pracę zanim zrobi się z niej techniczny bałagan.
- Jedna kolekcja na jeden obszar - nie mieszam wszystkiego w jednym zbiorze.
- Jedno źródło zmiennych - adresy, tokeny i identyfikatory trzymam w środowiskach.
- Przykłady odpowiedzi - dodaję je od razu, zanim nikt już nie pamięta, skąd się wzięły dane.
- Minimalny zestaw testów - każdy ważny request ma przynajmniej kilka sprawdzeń podstawowych.
- Brak sekretów w dokumentacji - dane wrażliwe nie mogą trafiać do publicznych opisów ani przykładów.
Jeśli mam wskazać jeden nawyk, który robi największą różnicę, to jest nim traktowanie kolekcji, dokumentacji i testów jako jednego zestawu, a nie trzech osobnych bytów. Wtedy Postman przestaje być tylko wygodnym interfejsem do klikania, a staje się narzędziem, które naprawdę porządkuje pracę z backendem i API. Jeśli zaczniesz od jednej kolekcji, dwóch środowisk i kilku testów na krytycznych endpointach, reszta będzie już tylko konsekwencją tego porządku.