
Wybór między GraphQL a REST wpływa nie tylko na wygodę zespołu backendowego, ale też na wydajność frontendu, koszty utrzymania i tempo rozwoju produktu. W praktyce chodzi o to, czy lepiej pobierać dokładnie takie dane, jakich potrzebuje interfejs, czy postawić na prostszy model zasobów i standardowe operacje HTTP. Poniżej rozkładam ten temat na konkretne różnice, typowe scenariusze i decyzje, które naprawdę mają znaczenie w projektach API.
Najkrócej: GraphQL wygrywa przy złożonych widokach, REST przy prostych i stabilnych zasobach
- GraphQL pozwala klientowi precyzyjnie wskazać pola, więc ogranicza nadmiarowe dane i liczbę dodatkowych zapytań.
- REST jest zwykle prostszy w cache’owaniu, monitorowaniu i wystawianiu publicznych integracji.
- GraphQL wymaga większej dyscypliny w schemie, autoryzacji i limitowaniu złożoności zapytań.
- REST szybciej wdrożysz tam, gdzie API obsługuje przewidywalne operacje CRUD.
- W e-commerce i headless CMS często najlepiej działa model mieszany: REST dla integracji, GraphQL dla frontendu.
Na czym naprawdę polega różnica między GraphQL a REST
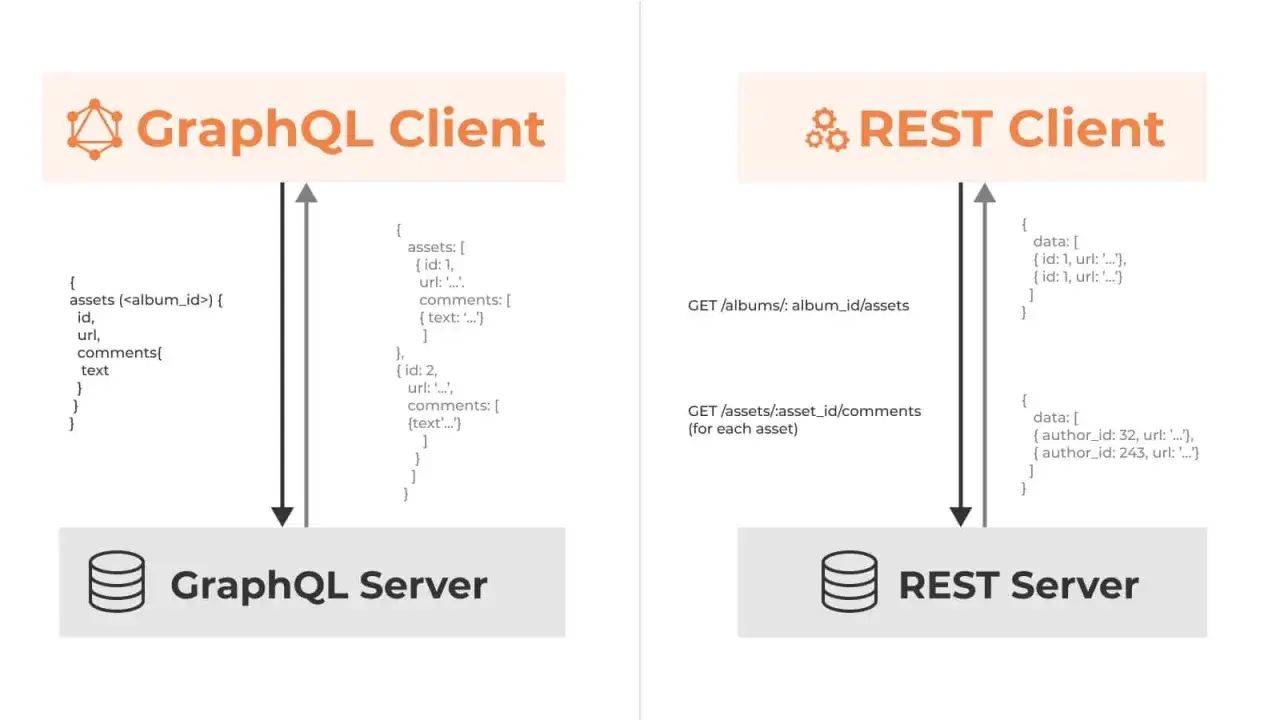
Najważniejsza różnica nie dotyczy samego HTTP, tylko modelu myślenia o danych. REST opiera się na zasobach i ich reprezentacjach, więc pracujesz na adresach URL, metodach typu GET, POST, PUT czy DELETE oraz na przewidywalnych odpowiedziach. GraphQL działa inaczej: klient zadaje pytanie przez schemę, a serwer zwraca dokładnie taki kształt danych, jaki został opisany w zapytaniu.
Dokumentacja GraphQL podkreśla, że API ma typowany schemat, a odpowiedź ma odzwierciedlać strukturę zapytania. Z kolei MDN opisuje REST jako zestaw ograniczeń architektonicznych wokół zasobów i standardowych interakcji klient-serwer. W praktyce przekłada się to na inną odpowiedzialność po obu stronach: w REST większą część decyzji podejmuje serwer, w GraphQL większą kontrolę dostaje klient.
To nie oznacza, że jeden model jest „nowocześniejszy”, a drugi „przestarzały”. Oznacza raczej, że każdy rozwiązuje inny problem. Gdy to rozumiesz, łatwiej ocenić, gdzie GraphQL daje przewagę, a gdzie tylko dokłada warstwę złożoności. I właśnie od tego zależy sensowny wybór technologii.
Kiedy GraphQL daje realną przewagę
GraphQL najlepiej sprawdza się tam, gdzie interfejsy są złożone, a jeden ekran potrzebuje danych z kilku miejsc naraz. Jeśli widok produktu ma pokazać nazwę, cenę, warianty, stany magazynowe, rekomendacje i treść z CMS, to GraphQL potrafi skrócić kilka wywołań do jednego. To nie tylko oszczędność czasu po stronie frontendu, ale też mniej szumu sieciowego i mniej kodu do składania odpowiedzi.
- Złożone frontendy - jedna strona agreguje dane z wielu domen, a każdy komponent potrzebuje innego wycinka informacji.
- Wiele klientów - web, mobile i panel administracyjny chcą tych samych danych, ale w różnym kształcie.
- Dynamiczny rozwój UI - projekt często zmienia układ sekcji, a backend nie powinien być przebudowywany przy każdym nowym widżecie.
- Aglomeracja źródeł danych - GraphQL dobrze nadaje się jako warstwa scalająca usługi, gdy logika jest rozproszona.
W dużych zespołach cenię też to, że schemę można traktować jak kontrakt między frontendem a backendem. Klient widzi dostępne pola, typy i zależności, a to ogranicza zgadywanie i przyspiesza pracę. Trzeba jednak pamiętać o cenie tej wygody: GraphQL wymaga porządnej autoryzacji na poziomie pól, sensownego cache’owania i kontroli złożoności zapytań. Bez tego szybciej pojawiają się problemy niż oszczędności.
Jeśli więc projekt ma wiele ekranów, częste zmiany i kilka źródeł danych, GraphQL bywa bardzo trafnym wyborem. Gdy takie wymagania nie występują, zysk szybko maleje, a wtedy warto spojrzeć w drugą stronę.
Kiedy REST jest rozsądniejszym wyborem
REST zwykle wygrywa, gdy API ma być proste, stabilne i łatwe do utrzymania przez dłuższy czas. Jeśli serwis udostępnia zasoby o dość przewidywalnej strukturze, to klasyczny model endpointów jest czytelny zarówno dla zespołu, jak i dla integratorów zewnętrznych. Nie trzeba tłumaczyć partnerom, jak działa schemat ani jak budować bardziej złożone zapytania - po prostu dostają konkretny URL i standardową metodę HTTP.
- Publiczne integracje - partnerzy i zewnętrzni deweloperzy łatwiej pracują z endpointami opartymi o zasoby.
- Proste CRUD - gdy dominują tworzenie, odczyt, aktualizacja i usuwanie danych, REST jest naturalny i ekonomiczny.
- Mocne cache’owanie - URL jako identyfikator zasobu dobrze współgra z cache HTTP, CDN i nagłówkami typu Cache-Control.
- Stabilne kontrakty - jeśli struktura danych zmienia się rzadko, REST zmniejsza ryzyko niepotrzebnej komplikacji.
REST ma też przewagę operacyjną. Łatwiej go obserwować, testować i debugować, bo żądania są bardziej „ludzkie” w analizie: widać zasób, metodę i kod odpowiedzi. W praktyce to skraca rozmowy między backendem, frontendem i DevOpsami. Dla wielu organizacji właśnie ta przewidywalność okazuje się ważniejsza niż możliwość budowania bardzo elastycznych odpowiedzi.
Nie traktowałbym REST-u jako rozwiązania mniej ambitnego. W wielu projektach to po prostu narzędzie lepiej dopasowane do problemu. A skoro oba podejścia mają mocne strony, sens ma dopiero porównanie ich w kilku konkretnych kryteriach.
Porównanie w praktyce dla backendu i produktu
| Kryterium | GraphQL | REST | Co to oznacza w praktyce |
|---|---|---|---|
| Model danych | Typowany schemat i pola wybierane przez klienta | Zasoby wystawione przez URL-e i metody HTTP | GraphQL daje większą elastyczność odpowiedzi, REST większą prostotę modelu |
| Liczba żądań | Często jedno zapytanie wystarcza do pobrania wielu zależnych danych | W złożonych widokach często potrzeba kilku endpointów | GraphQL dobrze ogranicza roundtripy, REST bywa bardziej rozproszony |
| Cache | Możliwy, ale zwykle wymaga bardziej świadomego podejścia | Natywnie dobrze współgra z cache HTTP i CDN | REST jest prostszy, gdy cache na brzegu sieci ma duże znaczenie |
| Wersjonowanie | Najczęściej rozwija się schemę bez twardych wersji, przez deprecacje | Często pojawiają się wersje typu /v1, /v2 | GraphQL ogranicza ból migracji, ale wymaga dyscypliny przy zmianach |
| Bezpieczeństwo | Trzeba kontrolować głębokość, koszt i złożoność zapytań | Łatwiej ograniczać per endpoint i metoda HTTP | GraphQL bez limitów potrafi być kosztowny operacyjnie |
| Debugowanie | Introspekcja i narzędzia typu GraphiQL pomagają odkrywać schemę | REST jest prostszy do śledzenia w logach i standardowych narzędziach HTTP | GraphQL przyspiesza eksplorację, REST upraszcza obserwację ruchu |
| Najlepsze zastosowanie | Frontend z wieloma zależnościami danych, mobile, kompozycja usług | Integracje, publiczne API, CRUD, content delivery | Wybór powinien wynikać z charakteru konsumowania danych, nie z mody |
Jeśli miałbym zamknąć to jednym zdaniem, powiedziałbym tak: GraphQL optymalizuje sposób, w jaki klient prosi o dane, a REST optymalizuje sposób, w jaki zasób jest wystawiony przez serwer. To różnica subtelna na slajdzie, ale bardzo odczuwalna w produkcji. Gdy interfejs jest bogaty i zmienny, elastyczność GraphQL-a potrafi skrócić ścieżkę od backendu do UI. Gdy zależy ci na prostocie i cache’owaniu, REST częściej wygrywa bez dyskusji.
W praktyce porównanie nie kończy się jednak na tabeli. Najwięcej problemów pojawia się wtedy, gdy zespół wybiera technologię bez uwzględnienia ograniczeń wdrożeniowych, a to właśnie prowadzi do typowych błędów.
Najczęstsze błędy przy wdrażaniu obu podejść
Najgorszy błąd, jaki widzę, to traktowanie GraphQL jak automatycznego lekarstwa na wydajność. Sam fakt, że klient może pobrać „tylko potrzebne pola”, nie gwarantuje szybkiego systemu. Jeśli resolvery są napisane naiwnie, pojawia się klasyczny problem N+1, czyli seria kosztownych odpytań do bazy zamiast jednego sensownego pobrania danych. Wtedy elastyczność schemy zaczyna kosztować więcej, niż oszczędza.
- Brak limitów złożoności - bez kontroli głębokości i kosztu zapytań GraphQL może być narażony na przeciążenie.
- Schema zrobiona 1:1 pod bazę - backend powinien odzwierciedlać potrzeby produktu, a nie strukturę tabel.
- Ignorowanie cache - zarówno w GraphQL, jak i REST cache trzeba zaprojektować, a nie „liczyć na szczęście”.
- Zbyt agresywne wersjonowanie REST - mnożenie /v1, /v2, /v3 często maskuje brak strategii rozwoju kontraktu.
- Brak jasnej autoryzacji - w GraphQL szczególnie ważne jest sprawdzanie dostępu do pól i relacji, nie tylko do endpointu.
Drugi częsty błąd to założenie, że REST z definicji musi być „prostszy”, więc nie wymaga żadnej architektury. W praktyce źle zaprojektowane endpointy, niespójne nazewnictwo i brak dokumentacji potrafią stworzyć bałagan większy niż średnio zbudowana warstwa GraphQL. Prosty styl nie zwalnia z odpowiedzialności za projektowanie API.
Dlatego przy wyborze podejścia patrzę nie tylko na funkcje, ale też na dojrzałość zespołu, plan rozwoju produktu i to, jak często dane będą używane w różnych kontekstach. Z tego przechodzę już do najważniejszego pytania: co wybrać w swoim projekcie.
Jak wybrać architekturę, która nie będzie przeszkadzać za pół roku
Jeśli projekt dopiero startuje, najpierw zadaję sobie trzy pytania: ilu klientów będzie używać API, jak często zmienia się model danych i czy odpowiedzi muszą być składane z wielu źródeł. Gdy odpowiedź na dwa pierwsze pytania brzmi „niewiele” i „rzadko”, REST zwykle wystarczy i da zespołowi spokojniejszy start. Gdy jednak frontend stale składa widoki z kilku serwisów, GraphQL szybko przestaje być ciekawostką, a staje się realnym ułatwieniem.
- Wybierz GraphQL, gdy masz złożone ekrany, wiele zależnych danych i różne potrzeby klientów.
- Wybierz REST, gdy budujesz stabilne, publiczne API albo klasyczne CRUD z prostymi zasobami.
- Rozważ model mieszany, gdy część systemu ma służyć integracjom, a część szybkiemu frontendu.
- Myśl o cache i obserwowalności od początku, bo to one zdecydują o kosztach utrzymania bardziej niż sam styl API.
W e-commerce i serwisach contentowych najczęściej widzę właśnie podejście mieszane: REST zostaje przy integracjach zewnętrznych, webhookach i prostych zasobach, a GraphQL trafia do warstwy prezentacji, która musi skleić produkt, treść, promocje i rekomendacje w jednym miejscu. To rozsądne, bo nie zmusza całej organizacji do jednej filozofii tylko po to, by wygrać dyskusję technologiczną. Jeśli miałbym zostawić jedną praktyczną zasadę, byłaby prosta: wybieraj nie to, co brzmi nowocześniej, ale to, co najczytelniej odpowiada na sposób korzystania z danych w twoim produkcie.