
Docker porządkuje etap, który w backendzie i API zwykle zabiera najwięcej czasu: zgranie wersji języka, bazy danych, cache i zależności tak, żeby aplikacja działała tak samo u każdego w zespole. Ja traktuję go przede wszystkim jako sposób na powtarzalność, a dopiero potem jako narzędzie do wdrożeń.
W tym artykule porządkuję podstawy Dockera z perspektywy praktyki: czym różni się obraz od kontenera, jak czytać Dockerfile, kiedy używać Compose i jakie błędy najczęściej psują pierwsze uruchomienia. To jest dokładnie ten zestaw, który najbardziej przydaje się przy pracy nad backendem, API i usługami towarzyszącymi, takimi jak baza czy Redis.
Najważniejsze rzeczy, które warto zapamiętać przed pierwszym kontenerem
- Obraz to gotowy pakiet z aplikacją i zależnościami, a kontener to jego uruchomiona instancja.
- Dockerfile opisuje, jak zbudować obraz, a Docker Compose pomaga uruchamiać kilka usług naraz.
- W backendzie Docker najbardziej pomaga tam, gdzie trzeba spiąć w jednej całości API, bazę danych, cache i kolejkę zadań.
- Największą korzyść daje spójne środowisko między laptopem, CI i serwerem, a nie sam „efekt nowości”.
- Dane, które mają przetrwać restart kontenera, trzeba trzymać w wolumenach, nie w systemie plików kontenera.
- Najczęstsze problemy to brak `.dockerignore`, zbyt ciężkie obrazy bazowe i mylenie startu kontenera z gotowością usługi.
Dlaczego Docker tak dobrze pasuje do backendu i API
W projektach backendowych problem rzadko polega na samym kodzie. Częściej chodzi o różnice w wersjach runtime, bibliotek, bazy danych albo narzędzi pomocniczych. Docker rozwiązuje ten chaos przez izolację środowiska, więc aplikacja uruchomiona lokalnie, w CI i na serwerze opiera się na tym samym opisie technicznym. To szczególnie ważne w e-commerce i serwisach contentowych, gdzie jeden drobny rozjazd w konfiguracji potrafi zablokować deploy albo wywołać trudny do odtworzenia błąd.
Ja patrzę na Docker przede wszystkim jak na warstwę standaryzacji. Nie zastępuje architektury, testów ani dobrego deploymentu, ale bardzo ogranicza liczbę miejsc, w których coś może pójść inaczej niż oczekujesz. W praktyce skraca onboarding, zmniejsza liczbę zgłoszeń w stylu „u mnie działa” i pozwala szybciej odtworzyć problem.
| Obszar | Bez Dockera | Z Dockerem |
|---|---|---|
| Uruchomienie backendu | Instalacja runtime, bibliotek i usług pomocniczych na systemie hosta | Jedno polecenie uruchamia środowisko opisane w obrazie |
| Spójność wersji | Ryzyko różnic między laptopem, CI i produkcją | Taki sam obraz można przenieść między środowiskami |
| Praca zespołowa | Każdy może mieć inny zestaw zależności | Zespół pracuje na tym samym opisie środowiska |
| Serwisy towarzyszące | Baza i cache są konfigurowane osobno, często ręcznie | API, baza i Redis mogą startować razem z Compose |
To dlatego Docker tak dobrze współgra z backendem. Gdy te korzyści są jasne, łatwiej zrozumieć, z czego właściwie składa się cały mechanizm i co w tym układzie robi każde narzędzie.
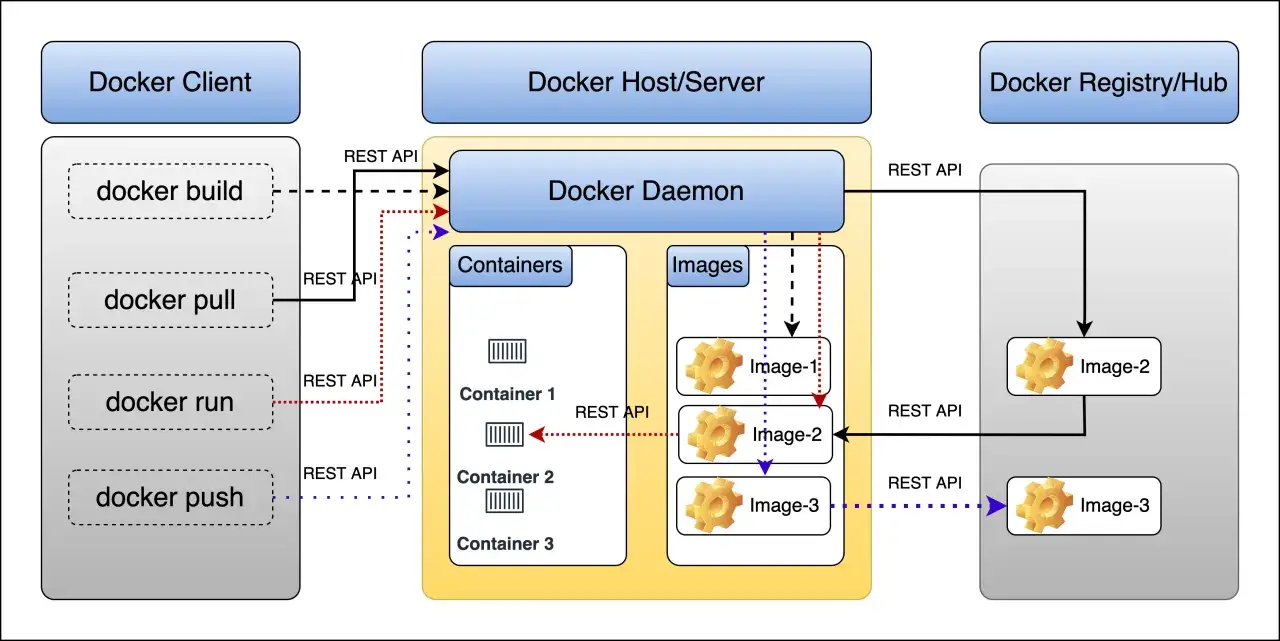
Jak działają kontenery, obrazy i Docker Compose
W oficjalnej dokumentacji Dockera te pojęcia są rozdzielone nie bez powodu. Jeśli na starcie wrzuci się je do jednego worka, później trudno zrozumieć, co jest gotowym pakietem, co jest uruchomioną instancją, a co tylko opisem budowy.
| Pojęcie | Co oznacza | Po co to w praktyce |
|---|---|---|
| Obraz | Niepodlegający zmianom pakiet z plikami, bibliotekami i konfiguracją | Budujesz raz i uruchamiasz wielokrotnie w różnych miejscach |
| Kontener | Uruchomiona instancja obrazu, czyli działający proces z własnym środowiskiem | Startujesz API, worker albo bazę w izolacji od systemu hosta |
| Dockerfile | Instrukcja, jak zbudować obraz krok po kroku | Opisujesz runtime, zależności, pliki i komendę startową |
| Registry | Repozytorium, w którym przechowuje się i udostępnia obrazy | Pobierasz gotowe obrazy lub publikujesz własne buildy |
| Wolumen | Trwałe miejsce na dane poza życiem pojedynczego kontenera | Przechowujesz bazę danych, uploady albo cache, który ma przetrwać restart |
| Docker Compose | Narzędzie do uruchamiania wielu usług z jednego pliku YAML | Spinasz backend, bazę, Redis i inne komponenty w jeden powtarzalny zestaw |
Najprościej mówiąc, obraz przygotowujesz, kontener uruchamiasz, a Compose składa z tego cały zestaw usług. Ta różnica wydaje się drobna, ale w praktyce decyduje o tym, czy projekt da się łatwo odtworzyć po miesiącu albo przenieść na inny serwer bez zgadywania ustawień.
Pierwsze uruchomienie własnego API bez zgadywania konfiguracji
Jeśli chcę szybko sprawdzić, czy podejście ma sens, zaczynam od jednego API. To najlepszy moment, żeby zobaczyć, jak działają porty, logi i cykl życia kontenera, zanim dołożysz bazę albo kolejny serwis.
docker build -t my-api:1.0 .
docker run --rm --name api -d -p 8080:8080 my-api:1.0
docker ps
docker logs -f api
docker stop apiNajważniejsze w tym zestawie poleceń jest mapowanie portów. W zapisie 8080:8080 pierwszy numer to port na hoście, a drugi to port wewnątrz kontenera. Dzięki temu aplikacja dostępna w kontenerze może odpowiadać na localhost:8080 na Twoim komputerze albo na serwerze testowym.
-
docker buildtworzy obraz z katalogu projektu. -
-t my-api:1.0nadaje obrazowi nazwę i tag, więc łatwiej go wersjonować. -
-duruchamia kontener w tle. -
--rmusuwa kontener po zatrzymaniu, co pomaga utrzymać porządek w środowisku lokalnym. -
docker logs -fpokazuje logi na żywo, więc szybciej widać błędy startu.
Gdy potrzebuję wejść głębiej, używam też docker exec -it api sh albo bash, jeśli obraz zawiera powłokę. To wygodne przy debugowaniu, ale nie powinno zastępować normalnych logów i testów. Sama możliwość wejścia do kontenera nie oznacza jeszcze, że obraz jest dobrze zbudowany. Dlatego kolejnym krokiem jest sensowny Dockerfile.
Jak napisać Dockerfile dla API, które nie spowalnia zespołu
Dockerfile to przepis na obraz. W backendzie i API najlepiej działa podejście proste: najpierw baza runtime, potem zależności, później kod aplikacji i na końcu komenda startowa. Ja zwykle zaczynam od takiego szkieletu, a dopiero później dopracowuję wieloetapowe buildy i inne optymalizacje.
FROM node:22-alpine
WORKDIR /app
COPY package*.json ./
RUN npm ci --omit=dev
COPY . .
EXPOSE 3000
CMD ["npm", "start"]Ten przykład jest prosty, ale pokazuje cały sens. Najpierw kopiujesz pliki z zależnościami, żeby Docker mógł użyć cache przy kolejnych buildach. Dopiero potem kopiujesz resztę kodu, więc zmiana jednego pliku aplikacji nie wymusza ponownej instalacji pakietów. To drobna rzecz, ale w praktyce potrafi skrócić pracę całego zespołu.
| Instrukcja | Po co służy | Typowy błąd |
|---|---|---|
FROM |
Wskazuje obraz bazowy, na którym budujesz własny obraz | Wybór zbyt ciężkiego albo przypadkowego obrazu |
WORKDIR |
Ustala katalog roboczy wewnątrz obrazu | Chaotyczne ścieżki i trudniejsze debugowanie |
COPY |
Kopiuje pliki z hosta do obrazu | Kopiowanie całego repozytorium za wcześnie, bez cache |
RUN |
Wykonuje polecenia podczas budowy obrazu | Łączenie zbyt wielu operacji w jeden nieczytelny krok |
EXPOSE |
Opisuje port, którego obraz oczekuje | Mylenie tego z faktycznym wystawieniem portu na hosta |
CMD |
Ustawia domyślną komendę startową kontenera | Wpychanie do obrazu logiki, która powinna być parametrem uruchomienia |
- Dodaj plik
.dockerignore, żeby nie pakować do obrazu rzeczy typunode_modules,distczy.git. - Rozważ multi-stage build, jeśli kompilujesz frontend, TypeScript albo binarkę i nie chcesz zostawiać narzędzi budowania w finalnym obrazie.
- Nie uruchamiaj aplikacji jako root, jeśli nie musisz.
- Przypinaj wersje obrazów bazowych zamiast polegać na nieokreślonym
latest.
Jeśli ten układ jest już jasny, łatwiej przejść do kolejnego poziomu, czyli uruchamiania całego stosu aplikacji, a nie samego API.
Jak spiąć API z bazą danych przez Docker Compose
W projektach backendowych Compose robi największą różnicę wtedy, gdy aplikacja przestaje być samotnym procesem, a zaczyna zależeć od bazy, cache albo kolejki. Wtedy ręczne odpalanie kilku kontenerów szybko staje się męczące, a jeden plik YAML jest zwyczajnie wygodniejszy i mniej podatny na pomyłki.
services:
api:
build: .
ports:
- "8080:8080"
environment:
DATABASE_URL: postgresql://postgres:postgres@db:5432/app
depends_on:
db:
condition: service_healthy
db:
image: postgres:16-alpine
environment:
POSTGRES_DB: app
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
volumes:
- db-data:/var/lib/postgresql/data
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres -d app"]
interval: 5s
timeout: 3s
retries: 10
volumes:
db-data:W tym przykładzie najważniejsze są dwie rzeczy. Po pierwsze, dane Postgresa trafiają do wolumenu, więc nie znikają po usunięciu kontenera. Po drugie, API nie powinno zakładać, że baza jest gotowa dokładnie w tej samej sekundzie, w której Compose uruchomił cały zestaw. Dlatego healthcheck i retry w aplikacji są rozsądniejszym podejściem niż ślepa wiara w kolejność startu.
-
docker compose up -d --buildbuduje obraz i uruchamia cały stack. -
docker compose logs -f apipozwala śledzić logi konkretnej usługi. -
docker compose downzatrzymuje kontenery, ale nie usuwa wolumenów. -
docker compose down -vusuwa też wolumeny, więc robi porządek, ale kasuje dane.
Właśnie tu widać praktyczny sens Dockera dla backendu. Zamiast pamiętać kilka ręcznych kroków, opisujesz usługę, bazę i sposób ich uruchamiania raz, a potem odtwarzasz środowisko jednym poleceniem. Na tym etapie najłatwiej jednak o błędy, które nie wynikają z samego narzędzia, tylko z nawyków wyniesionych z klasycznego uruchamiania lokalnego.
Błędy, które najczęściej psują pierwsze wdrożenia
Największe problemy przy pierwszym kontakcie z Dockerem rzadko są technicznie skomplikowane. To zwykle zestaw drobnych zaniedbań, które później wydłużają buildy, psują dane albo utrudniają debugowanie. Ja traktuję te błędy jako obowiązkową listę kontrolną, bo właśnie one potrafią najbardziej zaskoczyć początkujących.
- Brak
.dockerignorepowoduje, że do obrazu trafia za dużo plików, a build staje się wolniejszy i cięższy. - Trzymanie bazy danych w zwykłym kontenerze bez wolumenu kończy się utratą danych po restarcie.
- Używanie jednego kontenera do aplikacji i bazy utrudnia skalowanie, backup i diagnozę problemów.
- Zakładanie, że
depends_onoznacza gotowość usługi, prowadzi do błędów startu w API. - Poleganie na tagu
latestpsuje powtarzalność, bo obraz może zmienić się bez ostrzeżenia. - Uruchamianie wszystkiego jako root zwiększa ryzyko, a zwykle niczego nie upraszcza.
- Zbyt ciężki obraz bazowy zwiększa czas pobierania i wdrożenia, zwłaszcza w CI.
Jest jeszcze jedna granica, którą warto jasno nazwać. Docker nie naprawia słabego kodu, złego modelu danych ani źle zaprojektowanych zależności. Jeśli aplikacja ma problem z architekturą, kontener tylko uczciwie pokaże go szybciej, zamiast go ukryć. Dlatego kolejne decyzje warto podejmować już świadomie, a nie tylko „bo tak się robi”.
Co warto wdrożyć od razu, żeby Docker naprawdę pomagał
Jeśli wdrażam Dockera w nowym backendzie, zaczynam od kilku prostych zasad. Po pierwsze, obraz ma być możliwie mały i przewidywalny. Po drugie, konfiguracja ma być oddzielona od kodu, więc zmienne środowiskowe i sekrety nie lądują w obrazie. Po trzecie, dane trwałe zawsze trafiają do wolumenów, a nie do systemu plików kontenera. To wystarczy, żeby Docker realnie odciążył zespół, zamiast dokładać mu kolejnej warstwy chaosu.
- Używaj małych obrazów bazowych, ale tylko takich, które nadal pasują do Twojego stacku.
- Przypinaj wersje zależności i obrazów, żeby buildy były odtwarzalne.
- Rozdziel środowisko lokalne i produkcyjne, jeśli różnią się sposobem uruchamiania usług.
- Dodaj healthchecki tam, gdzie usługi zależą od siebie nawzajem.
- Dokumentuj najważniejsze komendy, zwłaszcza
docker compose up -d --buildidocker compose down -v. - Jeśli projekt rośnie, rozważ osobne pliki Compose dla developmentu i produkcji.
W praktyce ten zestaw daje największy zwrot: mniej ręcznej konfiguracji, mniej niespodzianek przy wdrożeniu i prostszy start dla kolejnych osób w zespole. To właśnie dlatego Docker najlepiej sprawdza się nie jako efektowny gadżet, tylko jako uporządkowana baza pod backend, API i całą resztę usług, które muszą działać spójnie razem.