
WebSocket co to jest w praktyce? To protokół, który pozwala utrzymać stałe połączenie między przeglądarką a serwerem i wymieniać dane w obie strony bez ciągłego odpytywania API. Dzięki temu real-time działa płynniej w czacie, panelu administracyjnym, statusach zamówień czy live dashboardach. W tym tekście rozkładam temat na prostą definicję, działanie po stronie backendu, wdrożenie, ograniczenia i wybór między WebSocketem a lżejszymi alternatywami.
Najważniejsze fakty, które warto mieć pod ręką
- WebSocket utrzymuje jedno stałe połączenie i umożliwia komunikację dwukierunkową bez nowego requestu dla każdej wiadomości.
- Protokół startuje od zwykłego handshake HTTP, a po udanej negocjacji przechodzi w tryb sesji czasu rzeczywistego.
- Najlepiej sprawdza się tam, gdzie liczy się niskie opóźnienie: chat, powiadomienia, monitoring, live tracking, gry, współpraca w czasie rzeczywistym.
- W backendzie kluczowe są nie tylko same wiadomości, ale też autoryzacja, reconnect, heartbeat, limity i skalowanie wielu połączeń jednocześnie.
- Jeśli dane zmieniają się rzadko, zwykłe REST, polling albo SSE często będą prostsze i tańsze w utrzymaniu.
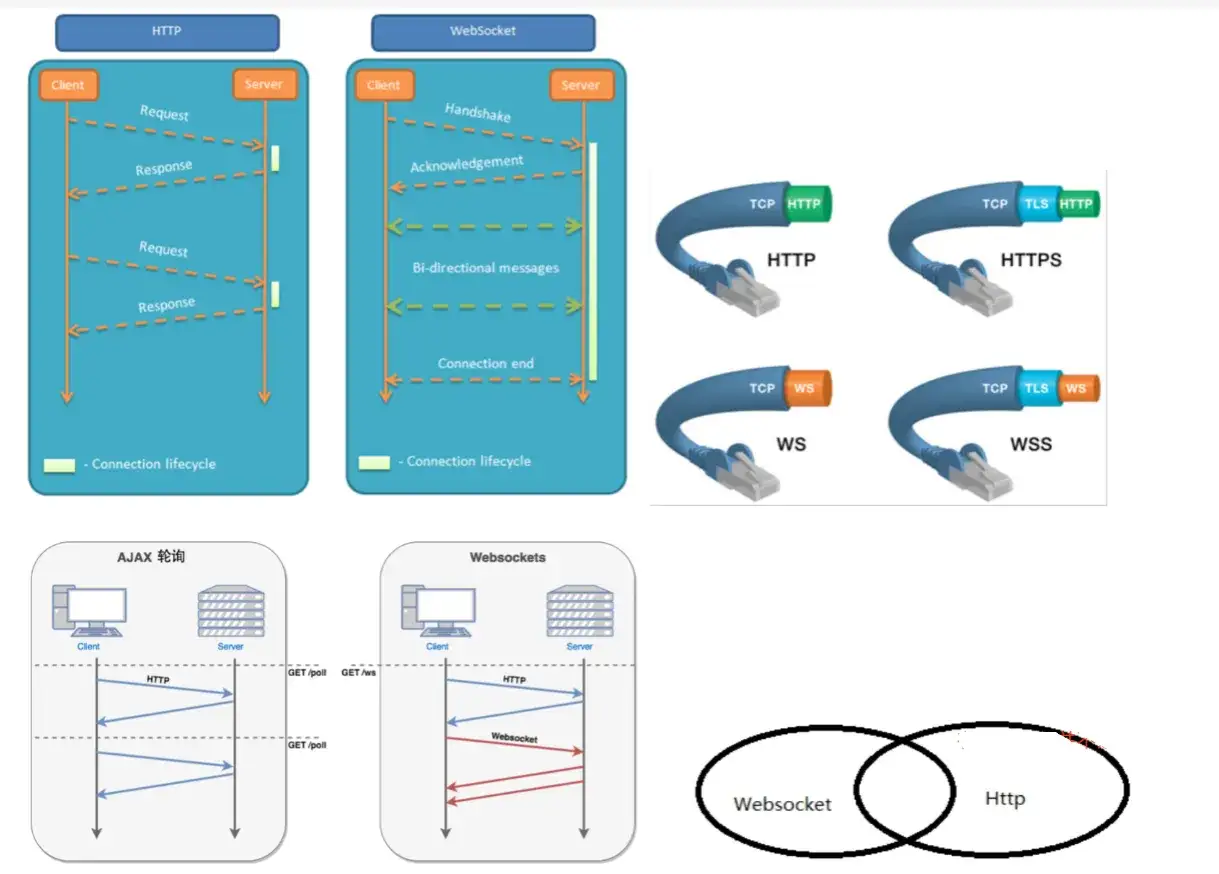
Jak działa WebSocket i dlaczego nie jest zwykłym request-response
Najkrócej: klasyczne HTTP działa w modelu żądanie-odpowiedź, a WebSocket utrzymuje jedno stałe połączenie, przez które obie strony mogą wysyłać dane wtedy, kiedy naprawdę coś się dzieje. RFC 6455 opisuje to jako handshake HTTP, który po akceptacji przechodzi w stałą komunikację nad TCP. To ważne, bo po zestawieniu sesji nie otwierasz nowego żądania dla każdej aktualizacji.
W praktyce masz tu kilka konsekwencji, które od razu czuć w aplikacji:
| Cecha | HTTP REST | WebSocket |
|---|---|---|
| Model komunikacji | Żądanie i odpowiedź | Dwukierunkowy kanał |
| Liczba połączeń | Wiele krótkich requestów | Zwykle jedno długie połączenie |
| Inicjacja danych | Najpierw klient pyta | Serwer może wysłać zdarzenie sam |
| Najlepsze zastosowanie | CRUD, treści, proste API | Real-time, statusy, czaty, live feed |
Warto też znać techniczne szczegóły, bo one mają znaczenie przy wdrożeniu. Protokół używa schematów ws:// i wss://; pierwszy domyślnie działa na porcie 80, drugi na 443 i jest szyfrowany TLS. Po stronie serwera udana negocjacja kończy się odpowiedzią 101 Switching Protocols, a nie klasycznym JSON-em z REST-a.
Jeśli to rozumiesz, łatwiej ocenisz, czy WebSocket jest realną potrzebą, czy tylko modną odpowiedzią na każdy problem. I właśnie od tego pytania przechodzę do praktyki zastosowań.
Kiedy WebSocket ma sens w backendzie i API
Ja zwykle zaczynam od prostego testu: czy użytkownik naprawdę musi dostać zmianę natychmiast, czy wystarczy mu odświeżenie co kilka sekund? Jeśli opóźnienie rzędu kilku sekund psuje doświadczenie, WebSocket zaczyna mieć sens. Jeśli nie, bardzo często lepszy będzie REST z pollingiem albo Server-Sent Events, zwłaszcza gdy dane płyną tylko z serwera do klienta.
W projektach e-commerce i SaaS WebSocket sprawdza się szczególnie dobrze w takich sytuacjach:
- czat obsługi klienta i komunikacja w czasie rzeczywistym,
- statusy zamówień, płatności i dostaw aktualizowane na żywo,
- pulpity administracyjne z wykresami i alertami,
- monitoring stanów magazynowych, dostępności produktów i cen,
- powiadomienia w aplikacji bez przeładowywania strony,
- wspólna edycja dokumentów, konfiguratorów lub tablic roboczych.
Są też scenariusze, w których nie pchałbym WebSocketu na siłę. Jeśli tworzysz klasyczne endpointy CRUD, panel CMS, blog albo formularze, które odświeżają się sporadycznie, zysk z przejścia na stałe połączenie bywa znikomy. W takich miejscach prostota API HTTP zwykle wygrywa z efektownością technologii.
Patrzę na to dość pragmatycznie: WebSocket ma sens tam, gdzie częstotliwość zdarzeń i niska latencja realnie wpływają na produkt. Jeśli to tylko „fajny dodatek”, architektura szybko robi się cięższa, niż powinna. Następny krok to już wdrożenie, bo tu zwykle zaczynają się konkretne decyzje.
Jak wygląda wdrożenie po stronie klienta i serwera
Najlepiej działa prosty podział ról. Po stronie przeglądarki otwierasz jedno połączenie, słuchasz zdarzeń open, message, error i close, a backend utrzymuje kontrakt wiadomości i wie, komu co wysłać. W praktyce najwygodniej sprawdza się format JSON z polem type, dzięki któremu jeden kanał przenosi różne zdarzenia, np. nową wiadomość, aktualizację statusu płatności albo alert o zmianie ceny.
const socket = new WebSocket('wss://api.example.pl/live');
socket.addEventListener('open', () => {
socket.send(JSON.stringify({
type: 'subscribe',
channel: 'orders'
}));
});
socket.addEventListener('message', (event) => {
const payload = JSON.parse(event.data);
console.log(payload);
});
socket.addEventListener('close', () => {
console.log('Połączenie zamknięte');
});Po stronie backendu myślę zwykle o czterech rzeczach naraz:
- autoryzacja - weryfikuję użytkownika już przy handshake'u, a nie dopiero po kilku wiadomościach,
- subskrypcje - nie wysyłam wszystkim wszystkiego, tylko do konkretnych kanałów albo pokoi,
- reconnect - klient powinien umieć podnieść połączenie ponownie po zerwaniu,
- heartbeat - ping/pong lub podobny mechanizm pomaga wykryć martwe sesje, zanim użytkownik sam to zauważy.
Przy dłuższych sesjach dobrze jest też przewidzieć rotację tokenów, czyszczenie starych połączeń i limity wiadomości. Ja zwykle projektuję backend tak, jakby rozłączenie było normalnym stanem, a nie wyjątkiem. To bardzo upraszcza życie, kiedy użytkownik zamyka kartę, przełącza sieć albo mobilny internet po prostu siada. I właśnie tutaj wychodzą na jaw problemy, które na papierze wyglądają niewinnie.
Gdzie najczęściej pojawiają się problemy z wydajnością i utrzymaniem
Największy błąd, jaki widzę, to traktowanie WebSocketu jak zwykłego endpointu, tylko że dłuższego. To nie działa. Masz połączenia utrzymywane przez dłuższy czas, więc pojawiają się kwestie pamięci, limitów serwera, odświeżania tokenów, rozłączania kart przeglądarki i tego, co zrobić, gdy wiadomości przychodzą szybciej, niż aplikacja je przetwarza. MDN zwraca uwagę, że klasyczny WebSocket nie zapewnia backpressure, więc przy dużym strumieniu danych możesz zacząć buforować za dużo albo przeciążyć CPU.
W praktyce pomaga kilka prostych zasad:
- ograniczaj rozmiar wiadomości i nie wysyłaj nadmiarowych danych,
- grupuj zdarzenia, jeśli ich tempo jest zbyt wysokie,
- pilnuj, żeby reconnect miał losowy backoff, a nie agresywną pętlę,
- zamykaj połączenie po stronie klienta, gdy użytkownik opuszcza widok,
- trzymaj monitoring liczby aktywnych sesji i błędów zamknięcia.
Warto umieć czytać kody zamknięcia, bo one szybko mówią, co się stało z sesją. Poniżej skrócona ściąga z tych, które w praktyce pojawiają się najczęściej:
| Kod | Znaczenie | Co to zwykle oznacza w praktyce |
|---|---|---|
| 1000 | Normal closure | Połączenie zakończyło się poprawnie, bez błędu |
| 1001 | Going away | Serwer, przeglądarka albo karta znika z obiegu |
| 1002 | Protocol error | Wiadomość lub ramka nie spełnia wymagań protokołu |
| 1006 | Abnormal closure | Połączenie urwało się bez poprawnego zamknięcia |
| 1009 | Message too big | Serwer lub klient dostał wiadomość większą, niż powinien |
Jeśli naprawdę potrzebujesz lepszej kontroli przepływu, istnieje też WebSocketStream, ale nie traktowałbym go jako zamiennika o takim samym zasięgu jak klasyczny WebSocket. Dla większości projektów nadal wygrywa prostszy, dobrze opakowany standardowy kanał, pod warunkiem że od początku uwzględnisz ograniczenia produkcyjne. Z tego miejsca naturalnie przechodzimy do porównania z innymi sposobami dostarczania danych na żywo.
WebSocket, SSE i polling różnią się bardziej niż wygląda na pierwszy rzut oka
Nie wybierałbym transportu wyłącznie dlatego, że jest „najszybszy”. Czasem lepsza jest prostota. Jeśli potrzebujesz tylko jednokierunkowych aktualizacji z serwera do przeglądarki, Server-Sent Events są zwykle łatwiejsze do utrzymania, bo nie otwierają pełnego kanału dwukierunkowego. Jeśli natomiast klient też ma aktywnie wysyłać dane, WebSocket wraca na prowadzenie.
| Mechanizm | Kierunek | Największa zaleta | Największe ograniczenie | Kiedy wybrać |
|---|---|---|---|---|
| WebSocket | Dwukierunkowy | Jedno stałe połączenie i niskie opóźnienie | Większa złożoność backendu i utrzymania | Chat, live dashboard, statusy, współpraca w czasie rzeczywistym |
| SSE | Jednokierunkowy | Prostsze wdrożenie przy pushu z serwera | Klient nie wysyła zdarzeń tym samym kanałem | Powiadomienia, feedy, aktualizacje z jednego źródła |
| Long polling | Głównie serwer - klient | Łatwy start bez dużych zmian w architekturze | Więcej narzutu niż przy stałej sesji | Gdy potrzebujesz „prawie realtime”, ale nie chcesz dużej przebudowy |
| Polling HTTP | Klient pyta cyklicznie | Najprostszy model myślenia | Najwięcej zbędnych requestów przy częstych zmianach | Rzadkie aktualizacje, proste API, niski budżet złożoności |
Jeśli miałbym to sprowadzić do jednej zasady, powiedziałbym tak: WebSocket wybieram wtedy, gdy dwustronny realtime jest częścią produktu, a nie tylko ozdobą w specyfikacji. Gdy potrzebujesz wyłącznie pushu z serwera, SSE często jest bardziej eleganckie. Gdy zmiany są rzadkie, zwykłe HTTP robi robotę bez dokładania warstwy, którą potem trzeba stale obsługiwać.
W praktyce wybór nie jest więc „nowoczesne kontra stare”, tylko „czy koszt stałego kanału zwraca się w doświadczeniu użytkownika”. I to prowadzi do najważniejszej części: jak podjąłbym decyzję w realnym projekcie, zanim cokolwiek napiszę.
Jak ja wybieram kanał czasu rzeczywistego w projekcie
W projektach e-commerce i SaaS zwykle zaczynam od najtańszego rozwiązania, które spełnia wymagania. Jeśli wystarczy odświeżenie co kilka sekund, biorę REST z pollingiem albo SSE. Jeśli potrzebny jest czat, edycja współdzielona, live feed albo szybka synchronizacja stanu między klientem a serwerem, wybieram WebSocket i od razu projektuję kontrakt wiadomości, reconnect oraz limity.
- Czy dane muszą płynąć w obie strony, czy tylko z serwera do klienta?
- Czy opóźnienie poniżej sekundy realnie zmienia UX?
- Czy backend udźwignie długie połączenia i ich nagłe zrywanie?
- Czy mam monitoring, limity i jasną strategię zamykania sesji?
Jeżeli na dwa pierwsze pytania odpowiadasz „tak”, WebSocket zwykle ma sens. Jeśli nie, nie komplikowałbym architektury na siłę. W dobrze zaprojektowanym API czas rzeczywisty jest narzędziem do poprawy produktu, a nie celem samym w sobie, i właśnie tak najrozsądniej patrzeć na ten protokół w 2026 roku.