
Dobrze ułożona struktura html oszczędza czas przy każdym kolejnym projekcie. Ułatwia pracę przeglądarce, poprawia czytelność kodu i daje solidną bazę pod SEO, dostępność oraz dalszy rozwój strony. W tym artykule rozbijam na czynniki pierwsze, jak wygląda poprawny szkielet dokumentu, co naprawdę musi znaleźć się w nagłówku strony i jak budować treść tak, żeby kod był prosty w utrzymaniu.
Najważniejsze elementy poprawnego dokumentu HTML
- Na początku stawiamy
</code>, żeby przeglądarka działała w trybie standardowym. - Element główny powinien mieć ustawiony język, np.
lang="pl", bo pomaga to przeglądarkom, czytnikom ekranu i wyszukiwarkom. - W sekcji nagłówkowej najważniejsze są:
charset,titleiviewport. - Treść widoczna dla użytkownika należy do
body, a metadane i zasoby techniczne dohead. - Semantyczne znaczniki, takie jak
header,main,sectionczyfooter, porządkują stronę lepiej niż samediv. - Najwięcej problemów powodują braki w hierarchii, zagnieżdżeniu i powielaniu metadanych.
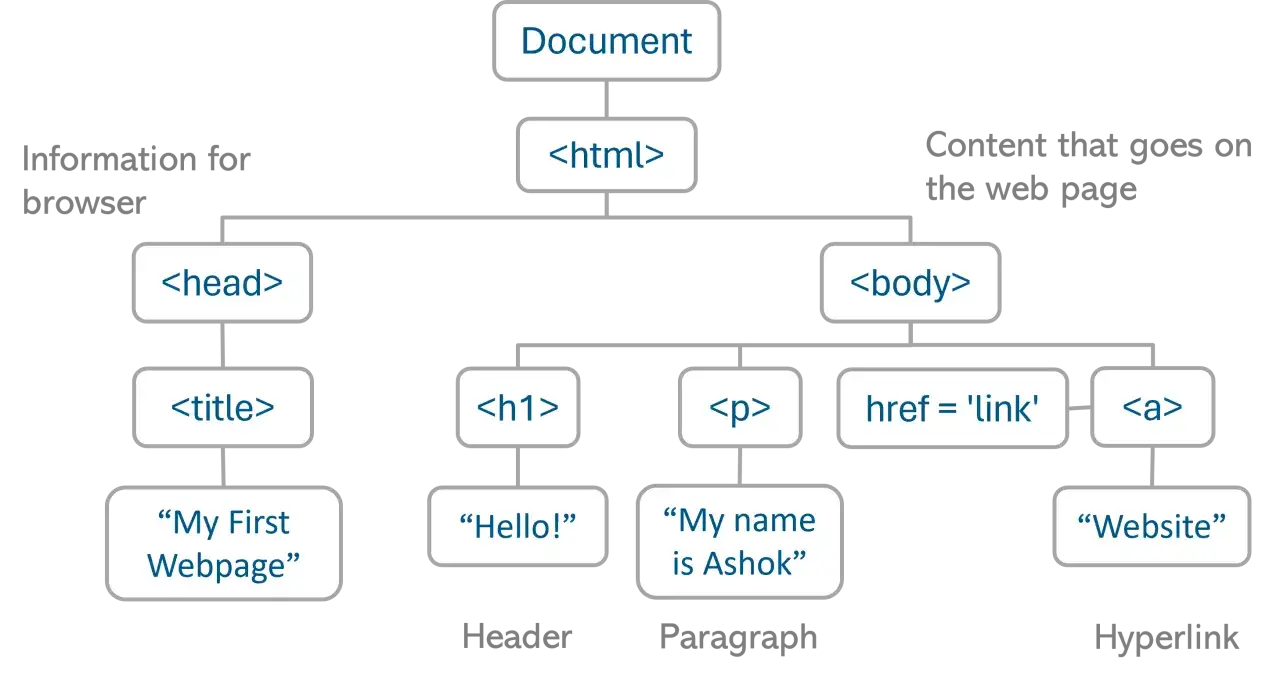
Jak wygląda podstawowy szkielet dokumentu
Najprostszy poprawny dokument HTML to nie zbiór przypadkowych tagów, tylko logiczny układ, w którym każda część ma swoje miejsce. Ja zaczynam od minimum, bo właśnie ono daje najlepszą bazę do dalszej rozbudowy, niezależnie od tego, czy tworzę blog, landing page, czy sklep internetowy.
Strona firmowa
Nagłówek strony
Główna treść.
Ten układ wygląda skromnie, ale w praktyce jest wystarczający, żeby strona była zrozumiała dla przeglądarki i dla człowieka. Najważniejsze jest to, że od razu widać podział na metadane i widoczną treść, więc później łatwiej rozwijać projekt bez chaosu. Następny krok to zrozumienie, co robi każdy z głównych fragmentów i dlaczego ich kolejność ma znaczenie.
Co robią doctype, element główny i sekcje dokumentu
</code> nie jest ozdobnikiem. To sygnał, że przeglądarka ma użyć trybu standardowego, zamiast próbować odtwarzać stare zachowania zgodności. W praktyce to różnica między przewidywalnym renderowaniem a debugowaniem dziwnych różnic w wyglądzie strony.
| Element | Rola | Dlaczego ma znaczenie |
|---|---|---|
</code> |
Włącza tryb standardowy | Zapobiega trybowi quirks i niestabilnemu renderowaniu |
|
Owija cały dokument | Określa język i porządkuje strukturę |
|
Przechowuje metadane | Obsługuje tytuł, kodowanie, SEO i zasoby techniczne |
|
Zawiera widoczną treść | To, co użytkownik faktycznie ogląda i klika |
Ja traktuję ten podział bardzo prosto: head opisuje stronę, a body jest jej treścią. Jeśli ten układ jest czytelny już na poziomie szablonu, później łatwiej zdecydować, gdzie wstawić styl, skrypt, sekcję z treścią lub element nawigacji. To prowadzi wprost do najważniejszej części nagłówka dokumentu.
Co powinno znaleźć się w head, a czego lepiej tam nie wciskać
W nagłówku dokumentu trzymam rzeczy, które wpływają na interpretację strony, ale nie są widoczne bezpośrednio w treści. Najpierw daję kodowanie znaków, potem tytuł, później ustawienia widoku mobilnego. Dopiero dalej dokładam opisy, ikony, arkusze stylów i inne metadane, jeśli projekt ich potrzebuje.
Elementy obowiązkowe
-
Charset - ustawiam go jako pierwszy, zwykle jako
, żeby uniknąć problemów z polskimi znakami. - Title - każdy dokument powinien mieć unikalny tytuł, bo to on trafia do zakładki przeglądarki, historii i wyników wyszukiwania.
- Viewport - bez niego strona może zachowywać się nieprzewidywalnie na telefonach i mniejszych ekranach.
- Lang - ustawiony w elemencie głównym pomaga czytnikom ekranu, tłumaczeniom i wyszukiwarkom poprawnie odczytać język strony.
Przeczytaj również: Jaki framework webowy wybrać? Poradnik wyboru i typowe błędy
Elementy zależne od projektu
-
meta name="description"- przydaje się, gdy chcesz lepiej opisać treść strony w kontekście wyszukiwania. -
link rel="icon"- porządkuje identyfikację strony w karcie przeglądarki i na urządzeniach mobilnych. -
link rel="canonical"- ma sens wtedy, gdy masz kilka wersji tej samej treści i chcesz wskazać wersję preferowaną. -
link rel="stylesheet"- służy do dołączania CSS, ale nie powinien mieszać się z widoczną treścią.
Nie wrzucam do head wszystkiego, co „się da”. To ma być miejsce na metadane i zasoby techniczne, nie magazyn na treść strony. Gdy te elementy są na swoim miejscu, można spokojnie przejść do struktury widocznej dla użytkownika.
Jak budować body, żeby kod był czytelny i semantyczny
body jest miejscem na to, co użytkownik faktycznie widzi. I tu najczęściej pojawia się pokusa, żeby wszystko zamknąć w kilku divach. Da się, ale to zwykle gorszy wybór, bo semantyczne elementy niosą znaczenie: pomagają w nawigacji po kodzie, w dostępności i w utrzymaniu projektu.
W praktyce najczęściej korzystam z takich bloków:
-
header- dla górnej części strony, zwykle z logo, menu i najważniejszym komunikatem. -
nav- dla głównej nawigacji, jeśli rzeczywiście jest osobnym elementem. -
main- dla głównej treści strony; powinien występować tylko raz w dokumencie. -
section- dla logicznych części jednego tematu, np. opisów funkcji, usług albo kategorii. -
article- dla treści samodzielnych, takich jak wpis blogowy, aktualność lub karta produktu, jeśli ma własny sens. -
aside- dla treści pobocznych, np. boksu z dodatkowymi informacjami albo powiązanych materiałów. -
footer- dla stopki, danych kontaktowych, linków pomocniczych i informacji prawnych.
Na stronie produktu w e-commerce ten podział działa szczególnie dobrze: w main umieszczam nazwę, zdjęcia, cenę, opis, warianty i przycisk zakupu, a elementy pomocnicze zostawiam na boku. Semantyka nie jest tu teorią, tylko sposobem na lepsze porządkowanie informacji. Gdy znasz już sens tych bloków, łatwiej uniknąć pomyłek, które w praktyce najbardziej komplikują projekt.
Najczęstsze błędy, które psują dokument
Najwięcej problemów nie bierze się z braku wiedzy o HTML, tylko z pośpiechu i przypadkowego kopiowania szablonów. Przeglądarka często „naprawi” kod po swojemu, więc strona się otworzy, ale to jeszcze nie znaczy, że dokument jest dobrze zbudowany.
- Brak
</code>, przez co przeglądarka może wejść w tryb zgodności zamiast standardowy. - Brak atrybutu
langalbo wpisanie złego języka dokumentu. - Wrzucanie metadanych do
bodyalbo widocznej treści dohead. - Chaotyczne zagnieżdżanie elementów, przez które znacznik końcowy zamyka nie to, co trzeba.
- Skakanie po hierarchii nagłówków bez logicznego układu, np. zbyt duży przeskok między poziomami.
- Zastępowanie semantycznych bloków samymi
divami, mimo że kod wymaga jasnego podziału. - Pomijanie
meta name="viewport", co szczególnie szkodzi na urządzeniach mobilnych.
Jeden z częstszych mitów dotyczy nagłówków: nie chodzi o to, żeby bezmyślnie pilnować jednego jedynego schematu, tylko o zachowanie logicznego porządku. Jeśli treść ma kilka sekcji, ich nagłówki muszą wynikać z układu strony, a nie z przypadku. Żeby wyłapać takie rzeczy przed publikacją, potrzebujesz krótkiej, powtarzalnej kontroli.
Jak sprawdzam, czy szablon jest gotowy do publikacji
W swoim workflow nie ufam wyłącznie temu, że strona „się otwiera”. Sprawdzam jeszcze kilka rzeczy, bo poprawność techniczna dokumentu i poprawne działanie w przeglądarce to nie zawsze to samo.
- Patrzę, czy
doctypejest pierwszą linią dokumentu. - Sprawdzam, czy
langodpowiada językowi strony. - Weryfikuję kolejność w
head: najpierw kodowanie, potem tytuł, potem ustawienia widoku. - Otwieram stronę w wąskim oknie i na telefonie, żeby szybko ocenić responsywność.
- Uruchamiam walidację HTML i prosty audyt, jeśli projekt jest większy albo ma więcej podstron.
W praktyce bardzo pomagają też narzędzia w przeglądarce, bo pokazują nie tylko efekt wizualny, ale i strukturę drzewa dokumentu. Ja zwykle sprawdzam jeszcze, czy tytuł jest sensowny, nagłówki nie dublują się bez potrzeby i czy treść nie została przypadkiem wrzucona do złej sekcji. Na koniec zostaje już tylko kilka zasad, które dobrze trzymać w każdym projekcie.
Co warto zachować w każdym projekcie, nawet prostym
Najlepsze szablony nie są rozbudowane, tylko konsekwentne. Jeżeli od początku pilnujesz porządnego szkieletu, odpowiednich metadanych i semantycznego body, kolejne podstrony łatwiej skalować, poprawiać i optymalizować pod SEO oraz dostępność.
- Zaczynaj od minimum - najpierw poprawny szkielet, dopiero potem dodatki i rozbudowa.
- Trzymaj metadane w head - to porządkuje dokument i zmniejsza ryzyko przypadkowych błędów.
- Buduj treść semantycznie - dzięki temu kod jest czytelniejszy dla ludzi i narzędzi.
- Myśl o mobilności od początku - viewport i układ sekcji mają znaczenie już na etapie pierwszego szkicu.
- Nie mieszaj warstw - treść, styl i logika dokumentu powinny być od siebie wyraźnie oddzielone.
Jeśli potraktujesz ten szkielet jako bazę, struktura html przestaje być przeszkodą, a staje się prostym standardem pracy, który pomaga budować czytelniejsze i łatwiejsze w utrzymaniu strony.