
Stylowanie stron zaczyna się od jednej decyzji: jak precyzyjnie wskazać element, który ma dostać dany wygląd. Gdy dobrze opanujesz selektory css, łatwiej zapanować nad nagłówkami, formularzami, kartami produktów i całymi sekcjami interfejsu bez walki z chaosem w arkuszu stylów. W tym artykule pokazuję, jak selektory działają, które typy warto znać, jak łączyć je bez przesady i jak unikać błędów, które potem kosztują najwięcej czasu.
Najważniejsze zasady selekcji elementów w CSS, które od razu porządkują pracę
- Selektor wskazuje, które elementy HTML mają otrzymać reguły CSS.
- Najbezpieczniejszym punktem startu są zwykle klasy, bo są czytelne i łatwe do utrzymania.
- Łańcuchy typu `header nav ul li a` działają, ale zbyt głębokie selekcje szybko robią się kruche.
- Specyficzność decyduje o tym, która reguła wygrywa, gdy kilka celuje w ten sam element.
- Nowoczesne pseudo-klasy, takie jak `:is()`, `:where()` i `:has()`, upraszczają kod, ale trzeba ich używać świadomie.
- Najlepszy selektor to ten, który jest krótki, czytelny i odporny na zmiany HTML.
Jak selektor wskazuje elementy i dlaczego to robi różnicę
Selektor w CSS to po prostu wzorzec dopasowania. Przeglądarka czyta go, porównuje z drzewem dokumentu i sprawdza, które elementy HTML spełniają warunek. Dopiero potem nakłada deklaracje z bloku reguły. To ważne, bo selektor nie jest ozdobnikiem przy nawiasie klamrowym, tylko filtrem decydującym o tym, co faktycznie zostanie ostylowane.
Najprostszy przykład to selektor typu, czyli nazwa znacznika. Jeśli wpiszesz `p`, przeglądarka styluje wszystkie akapity. Jeśli użyjesz `.product-card`, działa tylko na elementach z taką klasą. Ja zwykle zaczynam właśnie od tego pytania: czy chcę stylować typ treści, czy konkretny komponent. To rozróżnienie oszczędza sporo czasu już na etapie projektowania HTML.
p {
line-height: 1.7;
}
.product-card {
border: 1px solid #e5e7eb;
padding: 1.25rem;
}W praktyce ten sam fragment kodu może dać zupełnie inny efekt, jeśli selektor jest zbyt szeroki albo zbyt wąski. Gdy selektor jest za ogólny, przypadkiem łapie zbyt wiele elementów. Gdy jest za szczegółowy, robi się kruchy i trudno go później rozbudować. To prowadzi wprost do pytania, jakie typy selektorów naprawdę warto znać na co dzień.
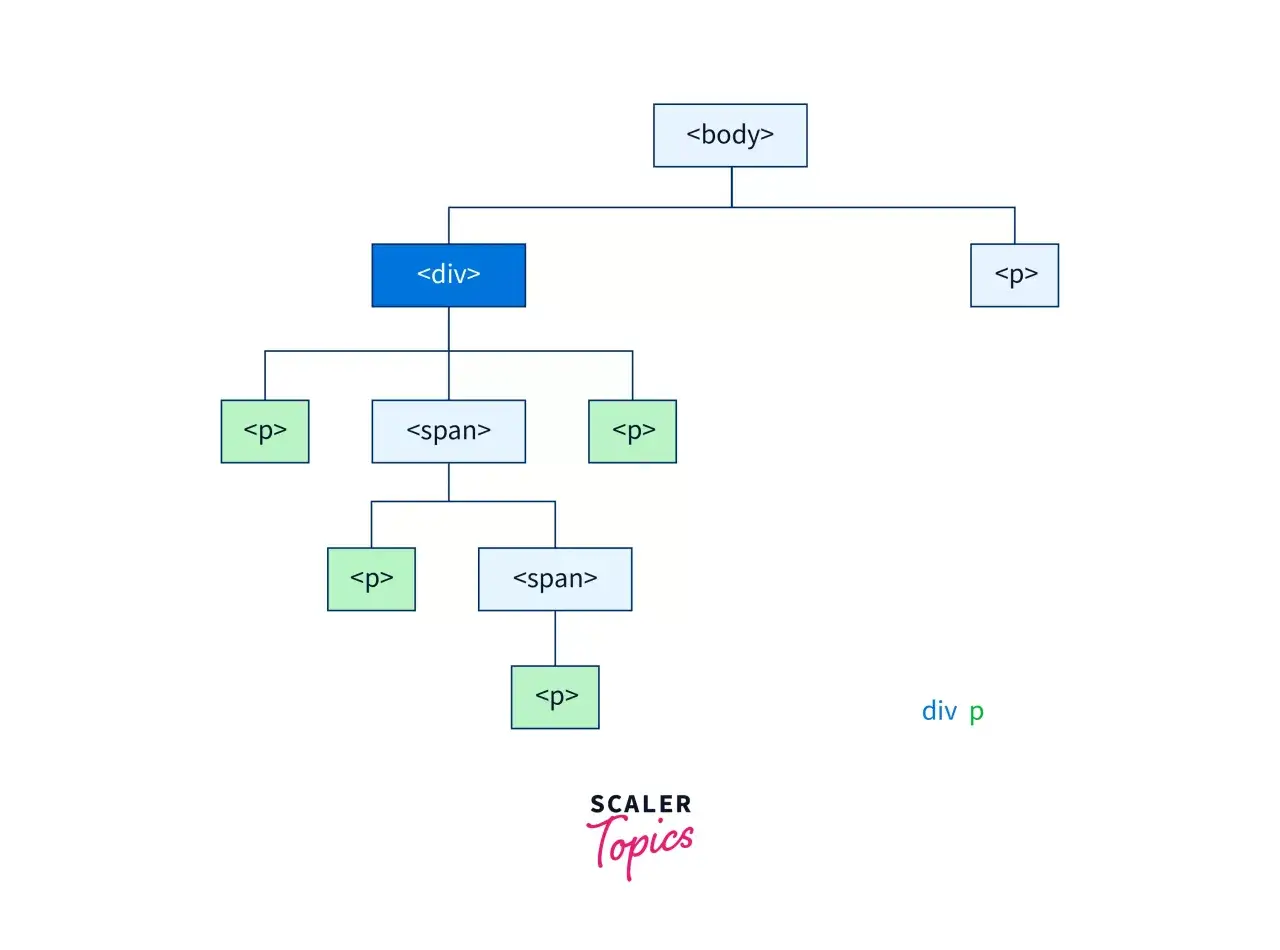
Najważniejsze rodzaje selektorów i kiedy używać każdego
W codziennej pracy nie potrzebujesz pamiętać wszystkiego naraz, ale warto znać grupy, które pojawiają się najczęściej. MDN opisuje ponad 60 selektorów i pięć kombinatorów, jednak w większości projektów powtarza się kilka podstawowych wzorców. Poniższa tabela porządkuje te, które realnie wykorzystuje się w stronach firmowych, blogach i sklepach internetowych.
| Rodzaj | Przykład | Kiedy używać | Na co uważać |
|---|---|---|---|
| Selektor typu |
p, h2, button
|
Gdy chcesz ustawić bazowy wygląd konkretnego tagu | Łatwo objąć nim więcej treści, niż planowałeś |
| Selektor klasy |
.card, .btn-primary
|
Do komponentów i wielokrotnego użycia | To zwykle najlepszy wybór, ale nazwy muszą być spójne |
| Selektor ID |
#kontakt, #main-nav
|
Do unikalnych miejsc na stronie, np. sekcji kotwicy | Ma wysoką specyficzność, więc trudniej go nadpisać |
| Selektor atrybutu |
[type="email"], [data-state="open"]
|
Gdy HTML niesie ważną informację o stanie lub wariancie | Świetny przy formularzach i UI opartym o atrybuty danych |
| Pseudo-klasa |
:hover, :focus-visible, :nth-child(2)
|
Do stanów interaktywnych i wyboru pozycji w strukturze | Stan elementu nie zawsze zależy tylko od HTML |
| Pseudo-element |
::before, ::after, ::first-line
|
Gdy stylujesz fragment elementu albo dodajesz dekorację | To nie są prawdziwe elementy DOM, więc używaj ich rozważnie |
Jeśli miałbym wskazać jedną praktyczną regułę, wybrałbym tę: klasy są najczęściej najbardziej opłacalne. Dają dobrą czytelność, dobrze współgrają z komponentami i nie przywiązują stylów zbyt mocno do struktury dokumentu. ID zostawiam raczej do kotwic, bardzo konkretnych wyjątków albo sytuacji, w których naprawdę wiem, że element jest jeden i tylko jeden. Z tej bazy naturalnie przechodzi się do łączenia selektorów, bo pojedynczy wzorzec nie zawsze wystarcza.
Jak łączyć selektory, żeby zawężać lub rozszerzać zakres
Same selektory to dopiero początek. Prawdziwa użyteczność pojawia się wtedy, gdy łączysz je z kombinatorami i grupowaniem. To one mówią przeglądarce, czy chodzi o element wewnątrz innego elementu, bezpośrednie dziecko, sąsiada czy dowolnego potomka. Dzięki temu możesz stylować precyzyjnie, ale nadal bez rozbijania HTML-u na nadmiar klas.
.article p {
margin-bottom: 1rem;
}
.article > p {
font-size: 1.05rem;
}
h2 + p {
margin-top: 0.25rem;
}
label + input {
margin-top: 0.5rem;
}Warto rozumieć cztery najczęstsze kombinatory. Spacja oznacza potomka, `>` bezpośrednie dziecko, `+` kolejny element rodzeństwa, a `~` dowolnego następnego brata. W praktyce spacja i `>` rozwiązują większość przypadków, ale `+` bywa świetny przy formularzach, listach i sekcjach treści, gdzie kolejność ma znaczenie. Ja najczęściej wybieram możliwie krótki zapis, bo im mniej zależności od głębokiej struktury, tym lepiej.
.filters .filter-group {
margin-bottom: 1rem;
}
.filters > .filter-group {
border-top: 1px solid #e5e7eb;
}
.card:hover .card__title {
color: #0f172a;
}Jest jeszcze grupowanie, czyli przecinek. Pozwala zastosować te same style do kilku selektorów naraz bez duplikowania deklaracji. To drobiazg, ale często porządkuje arkusz bardziej niż kolejne klasy pomocnicze. Gdy już wiesz, jak zawężać obszar działania reguł, naturalnie pojawia się kolejne pytanie: co zrobić, gdy dwie reguły chcą stylować to samo miejsce?
Specyficzność, czyli czemu jedne reguły wygrywają z innymi
Specyficzność to mechanizm, który rozstrzyga spory między selektorami. Jeśli dwie reguły trafiają w ten sam element i ustawiają tę samą właściwość, przeglądarka porównuje ich wagę. W uproszczeniu: im bardziej szczegółowy selektor, tym większa szansa, że wygra. MDN opisuje to jako algorytm oparty na liczbie selektorów w różnych kategoriach, a nie na „intuicji” przeglądarki.
Najprościej zapamiętać cztery poziomy: elementy i pseudo-elementy są najlżejsze, klasy, atrybuty i pseudo-klasy są cięższe, ID są jeszcze mocniejsze, a styl inline stoi wyżej niż większość reguł w arkuszu. W praktyce wygląda to mniej więcej tak:
-
pma mniejszą wagę niż.text -
.textma mniejszą wagę niż#content -
#contentzwykle wygra z prostą klasą, nawet jeśli klasa pojawi się później
To właśnie dlatego rozbudowane łańcuchy typu `header nav ul li a` bywają problematyczne. Są mocne, ale mało elastyczne. Z czasem jeden drobny refaktoring HTML-u psuje pół arkusza. Ja wolę podejście, w którym selektor jest możliwie krótki, a hierarchia wynika z sensownego nazewnictwa klas, nie z pięciu poziomów zagnieżdżeń.
.nav-link {
color: #334155;
}
.site-header .nav-link {
color: #0f172a;
}Ważny niuans: gdy kilka reguł ma tę samą specyficzność, decyduje kolejność w arkuszu. To oznacza, że nie zawsze problemem jest „zły selektor” - czasem po prostu reguła została zapisana zbyt wcześnie. Ten mechanizm dobrze zna każdy, kto kiedyś walczył z dziwnie nadpisującymi się stylami. Właśnie dlatego nowoczesne pseudo-klasy potrafią tak bardzo uprościć pracę.
Nowoczesne pseudo-klasy, które naprawdę ułatwiają pracę
W praktycznych projektach bardzo przydają się pseudo-klasy, bo pozwalają reagować na stan elementu albo jego pozycję w strukturze. `:hover` i `:focus-visible` są podstawą interakcji, `:nth-child()` pomaga przy powtarzalnych układach, a `:not()` pozwala wykluczać przypadki bez pisania dodatkowych klas. To nie jest już „fajny dodatek”, tylko normalne narzędzie pracy.
button:hover,
button:focus-visible {
transform: translateY(-1px);
}
li:nth-child(odd) {
background: #f8fafc;
}
input:not(:placeholder-shown) {
border-color: #22c55e;
}W 2026 roku szczególnie użyteczne są też `:is()`, `:where()` i `:has()`. `:is()` skraca długie listy podobnych selektorów, `:where()` robi to samo, ale bez podbijania specyficzności, a `:has()` pozwala stylować element na podstawie tego, co znajduje się w środku lub obok niego. MDN opisuje `:where()` jako selektor o zerowej specyficzności, a `:is()` jako taki, który przejmuje wagę najcięższego argumentu. To ważna różnica, bo od razu wpływa na utrzymanie kodu.
:is(h1, h2, h3) {
line-height: 1.2;
}
:where(.content, .sidebar) a {
text-decoration-thickness: 2px;
}
.card:has(img) {
padding-top: 0;
}`:has()` jest szczególnie praktyczny w komponentach, gdzie stan jednego elementu zależy od zawartości drugiego. Przykład? Karta produktu z obrazkiem, blok formularza z błędem albo sekcja, która dostaje inny układ, jeśli zawiera wideo. Trzeba tylko pamiętać, że mimo rosnącej dojrzałości wsparcia nadal warto sprawdzać kompatybilność, jeśli selektor ma sterować czymś krytycznym. Gdy już korzystasz z takich narzędzi, najłatwiej wpaść w kilka bardzo konkretnych pułapek.
Typowe błędy przy selektorach, które komplikują stylowanie
Najczęstszy błąd to nadmierna wiara w głębokie zagnieżdżenie. Początkujący często myślą, że im dłuższy selektor, tym lepsza kontrola. W praktyce bywa odwrotnie: kod robi się trudniejszy do nadpisania, bardziej zależny od struktury HTML i mniej odporny na zmianę komponentu. To szczególnie bolesne przy stronach rozwijanych etapami, gdzie layout żyje dłużej niż pierwszy projekt.
- Używanie ID do zwykłych komponentów zamiast klas.
- Stylowanie po strukturze tam, gdzie lepiej zadziałałaby semantyczna klasa.
- Tworzenie selektorów, które wyglądają jak ścieżka po DOM-ie, a nie jak reguła stylu.
- Ignorowanie stanów interaktywnych, takich jak focus, hover i disabled.
- Używanie `!important` jako sposobu na „naprawianie” specyficzności zamiast jej zrozumienia.
Drugi problem to brak konsekwencji w nazwach klas. Jeśli raz używasz `.btn-primary`, a obok `.button--accent`, arkusz zaczyna przypominać zbiór wyjątków zamiast systemu. W projektach ecommerce to bardzo szybko wychodzi przy przyciskach CTA, filtrach i kartach produktowych, gdzie komponenty są powtarzalne, ale wariantów jest dużo. Ja wolę nazwy, które od razu mówią, co to jest i w jakiej roli występuje.
Trzeci błąd jest bardziej subtelny: selektor działa, ale jest zbyt „podatny” na późniejsze zmiany. Na przykład stylowanie `main > section > article > p` wygląda precyzyjnie, tylko że wystarczy lekka przebudowa sekcji i reguła przestaje trafiać. To dobra lekcja, że dobry selektor nie powinien być kopią układu HTML. Powinien opisywać intencję projektową, a nie tylko bieżący kształt dokumentu. Z tego wynika praktyczne pytanie: jak dobierać selektory w prawdziwym projekcie strony lub sklepu?
Jak dobierać selektory w projekcie strony lub sklepu
W projektach, które rozwijają się przez miesiące albo lata, selektor powinien być stabilny. Dla treści artykułów najlepiej sprawdzają się proste zasady oparte na klasach kontenera, na przykład `.article`, `.content` albo `.rich-text`. Dzięki temu jeden blok stylów ogarnia nagłówki, listy, cytaty i obrazy bez rozlania się na resztę interfejsu. W e-commerce podobnie działa `.product-card`, `.price`, `.badge`, `.filter-panel` czy `.checkout-form`.
To podejście dobrze współgra z semantycznym HTML-em. Nagłówki oznaczam jako nagłówki, linki jako linki, formularze jako formularze, a selektory dopowiadam dopiero tam, gdzie naprawdę trzeba zawęzić styl. Daje to dwie korzyści: po pierwsze kod jest czytelniejszy dla zespołu, po drugie łatwiej go skalować bez przepisywania pół arkusza. W praktyce najbezpieczniejszy zestaw wygląda tak:
.article h2 {
margin-top: 2rem;
}
.product-card .price {
font-weight: 700;
}
.checkout-form [type="email"] {
width: 100%;
}Warto też rozdzielić warstwę bazową od wariantów. Jeśli masz przycisk podstawowy i jego odmiany, lepiej oprzeć je na wspólnej klasie komponentu niż kopiować selektory i nadpisywać pojedyncze właściwości. Taki model jest wygodny w rozwoju, bo nowy wariant dodajesz bez ruszania istniejących reguł. To właśnie w takich miejscach selektory przestają być tylko składnią, a stają się narzędziem porządku w projekcie.
Co zostaje w praktyce, gdy chcesz pisać lepsze style od razu
Najlepszy punkt wyjścia jest zaskakująco prosty: zaczynaj od klas, używaj selektorów typu tam, gdzie to naturalne, a złożone łańcuchy zostaw tylko wtedy, gdy naprawdę są potrzebne. W codziennej pracy najbardziej opłaca się pisać tak, aby kod był zrozumiały po trzech miesiącach, a nie tylko działał dziś. To podejście wygrywa z próbą „wyciśnięcia” wszystkiego z jednego wąskiego selektora.
Jeśli chcesz zapamiętać jedną rzecz, niech będzie to ta: dobry selektor opisuje intencję, a nie tylko pozycję elementu w DOM-ie. Właśnie dlatego klasy, rozsądne kombinatory i świadoma specyficzność dają lepszy efekt niż pogoń za maksymalną precyzją. Kiedy ten nawyk wejdzie w krew, CSS staje się dużo spokojniejszy, a poprawki przestają przypominać gaszenie pożaru.
W praktyce najwięcej daje konsekwencja: prosty system nazw, krótkie selektory i świadome korzystanie z pseudo-klas tam, gdzie poprawiają czytelność lub interakcję. To wystarczy, żeby budować arkusze stylów, które nie rozsypują się przy pierwszej zmianie layoutu.