
Magento API jest miejscem, w którym sklep zaczyna mówić do ERP, PIM, CRM i frontendu jednym, uporządkowanym językiem. W tym tekście pokazuję, czym ten interfejs naprawdę jest, kiedy lepiej wybrać REST, a kiedy GraphQL, jak wygląda autoryzacja oraz gdzie API daje największy efekt w e-commerce i CMS. Dorzucam też praktyczne ograniczenia, bo właśnie one najczęściej decydują o tym, czy integracja działa płynnie, czy zamienia się w serię poprawek.
Najważniejsze rzeczy o API Magento
- Najczęściej chodzi o integrację sklepu z systemami zewnętrznymi, a nie o jedną, zamkniętą funkcję.
- REST dobrze sprawdza się w integracjach backendowych, GraphQL w storefrontach i projektach headless, a SOAP głównie w zgodności ze starszymi rozwiązaniami.
- Autoryzacja i format adresów różnią się zależnie od typu wdrożenia, więc ten sam schemat nie zawsze zadziała wszędzie.
- Najbardziej opłacalne scenariusze to synchronizacja katalogu, stanów, zamówień, klientów i treści między systemami.
- Własne endpointy warto budować przez `webapi.xml` i service interfaces, a nie przez przypadkowe wystawianie wnętrza modułu.
- Bez testów, wersjonowania i kontroli uprawnień nawet dobra integracja potrafi rozjechać checkout albo dane klientów.
Czym jest interfejs API w Magento i po co się go otwiera
W najprostszej definicji chodzi o warstwę, która pozwala innym systemom bezpiecznie czytać i zapisywać dane sklepu. Magento API nie służy więc tylko programistom, ale każdemu, kto chce spiąć sprzedaż z operacjami: od importu produktów, przez obsługę zamówień, aż po synchronizację klientów i stanów magazynowych.
W praktyce to nie jest jeden monolit. Platforma udostępnia zasoby w modelu CRUD i wyszukiwania, a część logiki może być wystawiona tylko wtedy, gdy została jawnie opisana w konfiguracji modułu. To ważne, bo API nie pokazuje wszystkiego, co dzieje się wewnątrz systemu, tylko to, co zostało uznane za bezpieczne i użyteczne do integracji.
Ja zwykle patrzę na ten temat przez pryzmat procesu biznesowego. Jeśli sklep ma ręcznie pobierać zamówienia z panelu, eksportować stany do Excela i osobno aktualizować opisy produktów w CMS, to API nie jest dodatkiem. To warstwa, która usuwa powtarzalną pracę i ogranicza liczbę błędów ludzkich.
- Dla e-commerce API spina katalog, koszyk, zamówienia, płatności i fulfillment.
- Dla CMS pozwala pobierać dane produktowe, cenowe i contentowe do stron, landing page’y oraz aplikacji headless.
- Dla integracji B2B ułatwia wymianę danych z ERP, PIM, WMS i systemami sprzedaży zewnętrznej.
Gdy już wiadomo, po co w ogóle otwiera się tę warstwę, trzeba rozdzielić trzy główne warianty, bo każdy z nich służy trochę innemu zadaniu.
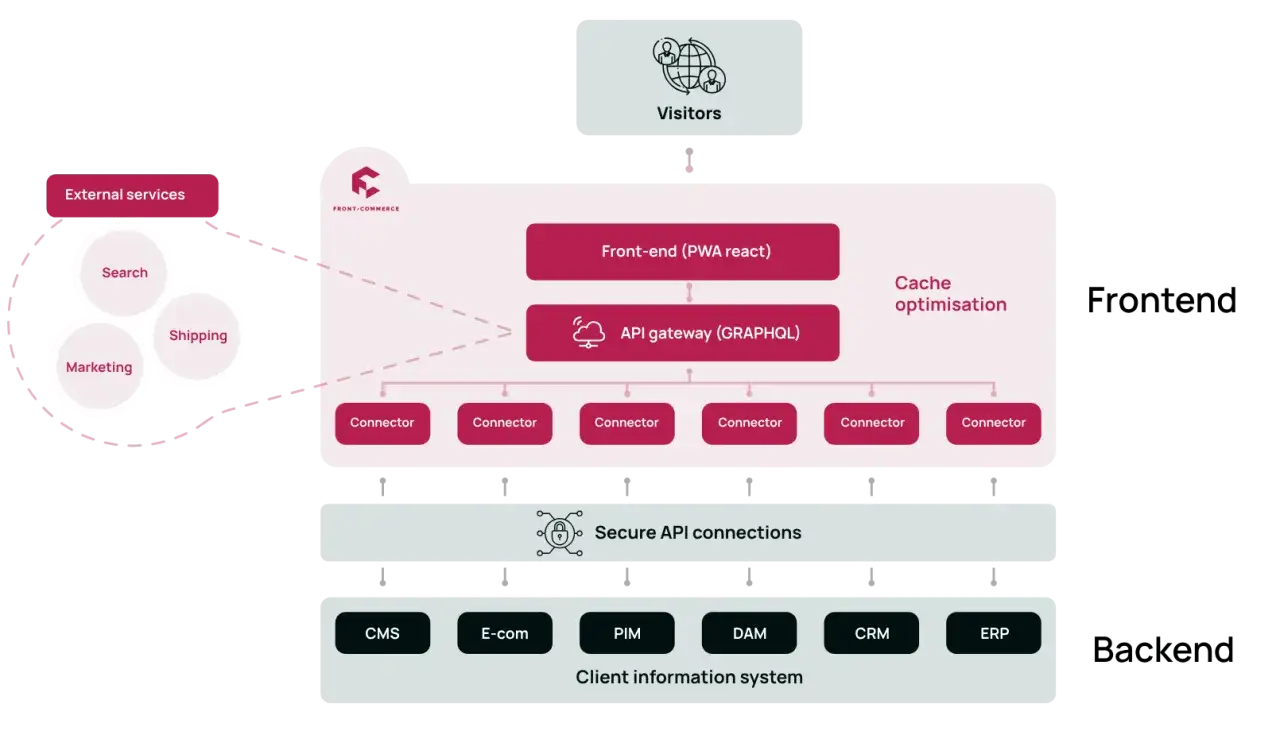
REST, GraphQL i SOAP do czego użyć każdego z nich
W dokumentacji Adobe Commerce REST i GraphQL są rozwijane równolegle, ale nie rozwiązują tego samego problemu. REST daje szeroki zestaw endpointów, GraphQL lepiej nadaje się do precyzyjnego pobierania danych na frontend, a SOAP pozostaje głównie tam, gdzie liczy się zgodność ze starszym środowiskiem.
| Interfejs | Kiedy wybrać | Mocne strony | Ograniczenia |
|---|---|---|---|
| REST | Integracje z ERP, PIM, OMS, importy i operacje administracyjne | Szeroki zakres zasobów, prosty model CRUD, dobra czytelność dla integratorów | Przy bardziej złożonych widokach wymaga zwykle więcej żądań i większej kontroli nad payloadem |
| GraphQL | Storefront, headless commerce, aplikacje mobilne, precyzyjne odczyty katalogu | Jeden endpoint, dokładnie określone pola, mniej nadmiarowych danych | Trzeba pilnować schematu, głębokości zapytań i wydajności |
| SOAP | Starsze integracje i systemy, które już są oparte na tym standardzie | Formalny kontrakt i dobra zgodność z legacy | Zwykle mniej wygodny i rzadziej najlepszy dla nowych projektów |
Jeśli projekt dotyczy sklepu headless, ja najczęściej zaczynam od GraphQL. Jeśli integracja ma zsynchronizować dane zewnętrzne, zwykle lepiej wypada REST. SOAP zostawiam tam, gdzie wymusza go stare środowisko albo gotowa platforma po drugiej stronie.
Warto pamiętać o jednej ważnej różnicy wdrożeniowej: w Adobe Commerce as a Cloud Service część REST-owych endpointów dla klientów i gości nie jest dostępna w takim samym zakresie jak w klasycznym wdrożeniu, a podobną funkcję często przejmuje GraphQL. To jedna z tych rzeczy, które trzeba sprawdzić przed rozpoczęciem pracy, bo inaczej architektura od początku idzie w złą stronę.
Gdy wybór jest już jasny, zaczynają się detale autoryzacji i adresowania żądań, a tam najczęściej wychodzą pierwsze błędy integracyjne.
Jak działa autoryzacja i struktura żądań
Magento udostępnia kilka modeli uwierzytelniania i to jest wygodne, ale też łatwo się na tym potknąć. Zależnie od typu klienta i środowiska możesz użyć OAuth 1.0a dla aplikacji zewnętrznych, tokenów dla aplikacji mobilnych albo danych logowania właściwych dla administratora i klienta. W nowszych wdrożeniach chmurowych dochodzi jeszcze IMS Access Token, który staje się obowiązkowy dla zapytań do odpowiednich usług.
Różni się też sam adres endpointu. W klasycznym REST najczęściej spotkasz strukturę w stylu /rest/. W Adobe Commerce as a Cloud Service scope sklepu jest przekazywany przez nagłówek Store, a sam adres wygląda inaczej, więc skopiowanie przykładu z innego środowiska bywa zdradliwe.
- POST, PUT i DELETE zwykle niosą dane w treści żądania.
-
GET do wyszukiwania często używa parametru
searchCriteriaw adresie URL. - Uprawnienia warto wiązać z rolą, a nie z luźnym tokenem przekazywanym wszędzie tak samo.
- Dane wrażliwe powinny wynikać z autentykacji, a nie być ręcznie podawane w parametrze, zwłaszcza przy identyfikatorach klienta czy koszyka.
To są drobiazgi techniczne tylko z pozoru. W praktyce właśnie one decydują o tym, czy integracja będzie stabilna, czy zacznie generować 401, 403 i trudne do zdiagnozowania różnice między środowiskiem testowym a produkcją.
Dopiero na takim fundamencie sensownie widać, gdzie API naprawdę usprawnia pracę sklepu i zespołu contentowego.
Do czego najczęściej wykorzystuje się to w sklepie i CMS
W projektach łączących CMS z e-commerce API robi największą różnicę tam, gdzie dane muszą płynąć między systemami bez ręcznej obróbki. To szczególnie ważne, gdy sklep ma rozbudowany katalog, osobny panel treści albo kilka kanałów sprzedaży naraz.
Najczęstsze zastosowania wyglądają bardzo konkretnie:
- Synchronizacja katalogu - produkty, atrybuty, ceny i stany magazynowe trafiają do Magento z PIM albo ERP, dzięki czemu dane nie żyją w trzech różnych wersjach.
- Obsługa zamówień - statusy, faktury, wysyłki i aktualizacje fulfillmentu mogą być automatycznie przekazywane do zewnętrznych systemów.
- Dane klientów - konta, adresy i segmenty klientów można spiąć z CRM lub programem lojalnościowym.
- Headless storefront - frontend pobiera tylko to, czego potrzebuje, zamiast odpytywać ciężkie warstwy renderujące.
- Treści i merchandising - opisy, banery, kolekcje i bloki contentowe mogą być zasilane z osobnego CMS, co ułatwia pracę zespołowi marketingu.
Jeśli mam wskazać jeden obszar, w którym API robi największą różnicę, to jest nim właśnie synchronizacja danych produktowych i orderowych. To tam najszybciej widać zwrot z automatyzacji, bo każdy ręczny eksport czy import kosztuje czas i zwiększa ryzyko pomyłki.
W praktyce to także świetny sposób na rozdzielenie odpowiedzialności: CMS odpowiada za treść, platforma sprzedażowa za handel, a API pilnuje, żeby oba światy mówiły tym samym językiem. Jeśli jednak katalog lub proces wymaga czegoś niestandardowego, trzeba wiedzieć, jak rozszerzyć platformę bez psucia architektury.
Jak dodać własny endpoint bez robienia bałaganu
Własny endpoint ma sens wtedy, gdy standardowe zasoby nie opisują realnego procesu biznesowego. W Magento robi się to przez moduł i konfigurację webapi.xml, w której definiujesz usługę, metody i uprawnienia. Jeśli usługi nie ma w konfiguracji, nie będzie wystawiona, więc to nie jest luźne „otwieranie” wszystkiego, tylko kontrolowana ekspozycja kontraktu.
Ja zwykle trzymam się kilku zasad, bo one oszczędzają bardzo dużo czasu później:
- Najpierw definiuję service interface, a dopiero potem myślę o implementacji.
- Wystawiam tylko te metody, które są naprawdę potrzebne, zamiast kopiować logikę całego modułu.
- Uprawnienia przypisuję do konkretnej roli lub integracji, żeby nie robić z endpointu publicznego skrótu do danych sklepu.
- Unikam zwracania surowych modeli i tabel, bo to mocno sprzęga API z wnętrzem systemu.
- Dodaję testy funkcjonalne dla każdego nowego endpointu, bo one najszybciej łapią regresje kontraktu.
To podejście ma jeszcze jedną zaletę: łatwiej potem utrzymać kompatybilność wsteczną. Klient integracyjny nie interesuje się tym, jak wygląda model danych wewnątrz modułu, tylko tym, czy endpoint zwraca stabilny i przewidywalny format.
Jeżeli trzeba rozbudować integrację o coś naprawdę specyficznego, lepiej stworzyć osobny, dobrze opisany endpoint niż doklejać logikę do istniejącego „na szybko”. Największe szkody zwykle robią jednak nie same endpointy, tylko błędy wdrożeniowe i zbyt optymistyczne założenia.
Najczęstsze błędy, które kosztują najwięcej czasu
Najwięcej problemów w integracjach API nie bierze się z samego Magento, tylko z decyzji podjętych na początku projektu. Z mojej perspektywy powtarza się kilka błędów szczególnie często.
- Zły wybór interfejsu do zadania - ktoś buduje ciężką synchronizację przez GraphQL albo skleja frontend z REST-em tylko dlatego, że „tak było szybciej”.
- Brak jednego źródła prawdy - ceny, stany i opisy żyją równolegle w kilku systemach, więc po tygodniu nikt nie wie, który rekord jest właściwy.
- Zbyt duże zapytania - szczególnie w GraphQL łatwo przesadzić z głębokością i objętością odpowiedzi; domyślny limit głębokości bywa ustawiony na 20, więc rozbudowane drzewka trzeba planować rozsądnie.
- Pomijanie stagingu i testów - API działające na lokalnym środowisku potrafi rozbić checkout dopiero przy realnym ruchu.
- Ignorowanie różnic między wdrożeniami - klasyczny Magento i cloud service nie zachowują się identycznie, zwłaszcza jeśli chodzi o scope i dostępność części REST-owych zasobów.
- Brak planu na ruch i awarie - jeśli integracja ma wysyłać setki żądań na minutę, trzeba przewidzieć kolejkowanie, retry i ograniczanie ruchu po stronie własnej infrastruktury.
- Zakładanie, że pojawią się webhooki - w tym ekosystemie nie wszystko działa event-driven natywnie, więc czasem potrzebna jest kolejka, cron albo warstwa pośrednia.
W takich projektach bardzo pomaga zasada: najpierw prosty kontrakt, potem skala. Gdy próbujesz od razu zbudować „idealną” integrację na wszystkie przypadki, kończysz z rozwiązaniem, którego nikt nie chce utrzymywać.
Na końcu zostaje już tylko sprawdzić, czy przed wejściem na produkcję wszystkie decyzje są naprawdę domknięte, a nie tylko „na papierze”.
Co sprawdziłbym przed wdrożeniem na produkcję
Przed uruchomieniem integracji zawsze sprawdzam kilka rzeczy w tej samej kolejności. To nudne, ale skuteczne, a w projektach e-commerce nudna przewidywalność jest cenna.
- Kto jest właścicielem danych - czy źródłem prawdy jest ERP, PIM, CMS czy Magento.
- Jakie dane są tylko do odczytu - szczególnie przy cenach, stocku i treściach promocyjnych.
- Jak wygląda autoryzacja - tokeny, role, rotacja sekretów i obsługa wygasania dostępu.
- Co ma iść synchronicznie, a co asynchronicznie - zamówienia zwykle wymagają innego traktowania niż masowy import katalogu.
- Jakie są limity i fallback - timeouty, retry, kolejki oraz zachowanie przy częściowym błędzie.
- Jak monitorujesz błędy - logi bez tego szybko stają się bezużyteczne.
Jeśli miałbym zamknąć temat jednym praktycznym wnioskiem, powiedziałbym tak: GraphQL wybieraj tam, gdzie liczy się frontend i precyzyjny odczyt danych, REST tam, gdzie integrujesz systemy operacyjne, a własny endpoint twórz dopiero wtedy, gdy standardowy model naprawdę nie wystarcza. Taki porządek pozwala budować sklep, który da się rozwijać bez chaotycznego dłubania w integracjach za każdym razem, gdy zmienia się proces biznesowy.