
Solidny backend decyduje o tym, czy aplikacja tylko działa, czy naprawdę skaluje się, chroni dane i dobrze współpracuje z płatnościami, magazynem, CMS-em albo CRM-em. To właśnie tutaj zaczyna się backend development: warstwa logiki, danych i API, której użytkownik nie widzi, ale bez której sklep, panel klienta czy SaaS szybko traci sens. W tym tekście rozkładam temat na praktyczne elementy: co robi zaplecze aplikacji, jak przepływają żądania, jakie modele komunikacji mają sens i gdzie najczęściej pojawiają się kosztowne błędy.
Najpierw porządek w pojęciach, potem decyzje, które realnie wpływają na projekt
- Backend odpowiada za logikę biznesową, dane, uprawnienia i integracje, a frontend tylko pokazuje efekt tej pracy.
- API to kontrolowana umowa między klientem a serwerem, najczęściej oparta na HTTP i JSON.
- REST sprawdza się w większości klasycznych projektów, a GraphQL, webhooki i gRPC rozwiązują bardziej konkretne problemy.
- Bezpieczeństwo w API najczęściej psują błędy autoryzacji, brak limitów i zbyt szeroki dostęp do danych.
- Wydajność zwykle poprawiają paginacja, cache, kolejki i małe, dobrze opisane odpowiedzi.
- Modularny monolit bardzo często wygrywa z mikroserwisami na starcie, bo jest prostszy w utrzymaniu.
Czym właściwie zajmuje się zaplecze aplikacji
Backend odpowiada za to, co dzieje się za kulisami: przyjmuje żądania, sprawdza uprawnienia, wykonuje reguły biznesowe, zapisuje dane i zwraca odpowiedź, którą frontend potrafi wyświetlić. W sklepie internetowym będzie to koszyk, ceny po rabatach, dostępność produktów, status zamówień, płatności i integracje z kurierami albo ERP.
W projektach contentowych zaplecze ma też wpływ na SEO pośrednio przez szybkość odpowiedzi, poprawne przekierowania, mapę strony, dane strukturalne i spójność adresów. Strona może wyglądać dobrze, ale jeśli serwer zwleka albo zwraca chaos w URL-ach, użytkownik i wyszukiwarka od razu to odczują.
- Walidacja danych - zanim cokolwiek trafi do bazy, backend sprawdza poprawność formularza, typów i reguł biznesowych.
- Autoryzacja - system decyduje, czy ten konkretny użytkownik może wykonać daną akcję.
- Logika biznesowa - tu liczy się nie tylko to, czy da się zapisać rekord, ale też czy wolno i w jakiej kolejności.
- Integracje - bramki płatności, kurierzy, ERP, newslettery, wysyłka SMS i analityka.
Jeśli ta warstwa jest dobrze zaprojektowana, frontend staje się prostszy, a cały projekt łatwiej rozwijać. Następny krok to zobaczenie, jak taki przepływ wygląda w praktyce od pierwszego requestu do odpowiedzi z serwera.
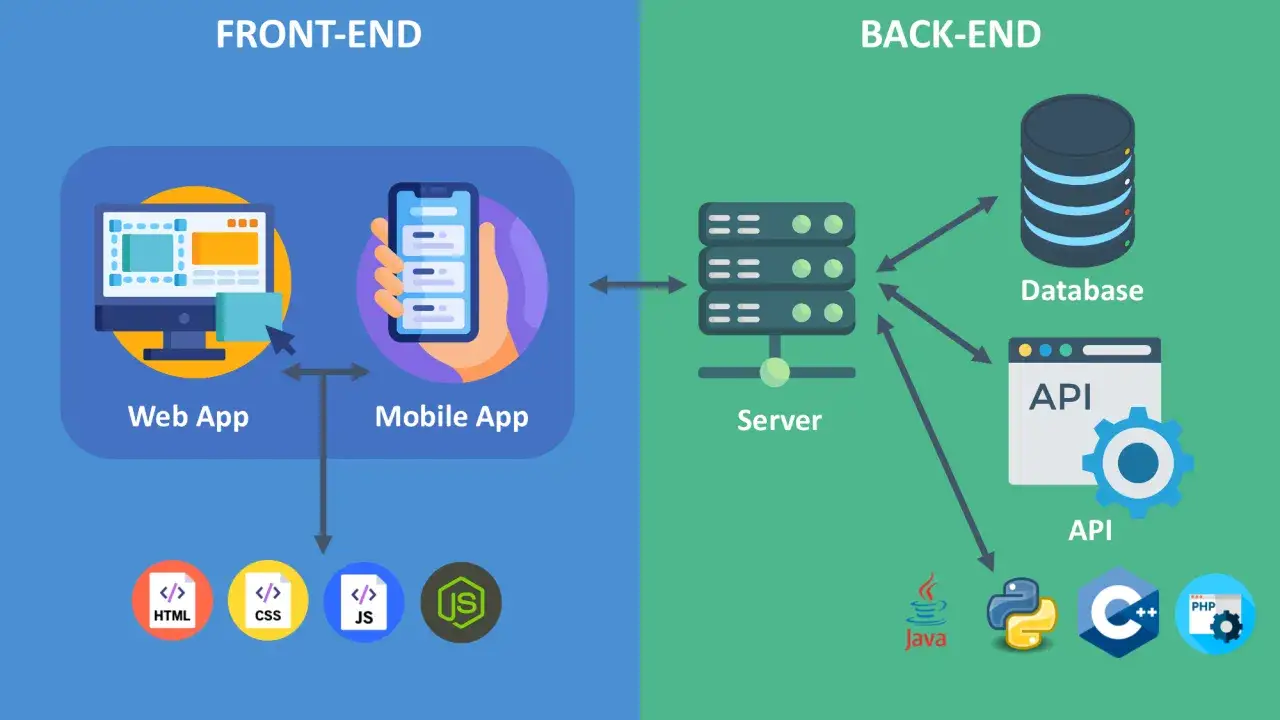
Jak przepływa żądanie między frontendem, API i bazą danych
API jest umową między klientem a serwerem. Nie jest bazą danych wystawioną na świat, tylko kontrolowanym wejściem do funkcji systemu. W dobrze zaprojektowanym przepływie frontend wysyła żądanie HTTP, backend je rozpoznaje, sprawdza kontekst użytkownika, pobiera dane z bazy lub z usług zewnętrznych i odsyła czytelną odpowiedź, najczęściej w JSON.
Największa korzyść z takiego podejścia jest prosta: frontend nie musi wiedzieć, jak wygląda tabela zamówień, a backend nie musi znać szczegółów interfejsu. Dzięki temu obie strony mogą rozwijać się niezależnie, o ile kontrakt jest opisany i stabilny.
| Kod | Kiedy ma sens | Co komunikuje |
|---|---|---|
| 200 OK | Gdy żądanie zakończyło się sukcesem i zwracasz dane | Operacja została wykonana poprawnie |
| 201 Created | Po utworzeniu nowego zasobu, na przykład zamówienia lub konta | Nowy rekord faktycznie powstał |
| 204 No Content | Gdy operacja się udała, ale nie ma potrzeby odsyłać body | Wynik jest pozytywny, lecz pusty |
| 400 Bad Request | Gdy dane wejściowe są niepoprawne albo brakuje wymaganych pól | Klient ma poprawić request |
| 401 Unauthorized | Gdy nie ma poprawnego uwierzytelnienia | Trzeba się zalogować lub odświeżyć token |
| 403 Forbidden | Gdy użytkownik jest znany, ale nie ma uprawnień | Ten zasób albo akcja są dla niego zablokowane |
| 404 Not Found | Gdy zasób nie istnieje albo nie powinien być ujawniony | Nie ma czego zwrócić |
| 409 Conflict | Gdy pojawia się konflikt stanu, duplikat lub równoległa zmiana | Klient musi ponowić akcję po rozwiązaniu konfliktu |
| 422 Unprocessable Entity | Gdy request jest składniowo poprawny, ale łamie reguły biznesowe | Dane trzeba poprawić logicznie, nie tylko technicznie |
| 429 Too Many Requests | Gdy użytkownik lub bot przekracza limity | Trzeba zwolnić tempo |
| 500 Internal Server Error | Gdy po stronie serwera dzieje się coś nieprzewidzianego | To błąd systemu, a nie użytkownika |
Nie warto zwracać zawsze 200, bo wtedy frontend i integracje tracą ważny sygnał o tym, co faktycznie się stało. Dobrze dobrany status HTTP oszczędza czas w debugowaniu i poprawia jakość całego kontraktu. Żeby to miało sens, trzeba jeszcze rozdzielić poszczególne warstwy zaplecza.
Z czego składa się sensowny backend
Ja zwykle rozbijam backend na warstwy, bo wtedy łatwiej wyłapać, gdzie powstaje problem i co trzeba testować. Jeśli wszystko ląduje w kontrolerze albo w jednym serwisie, debugowanie szybko zamienia się w zgadywanie.
| Warstwa | Za co odpowiada | Czego pilnować | Co zwykle się psuje |
|---|---|---|---|
| HTTP i routing | Przyjmuje żądania, rozpoznaje endpointy, parsuje parametry | Przejrzyste kontrolery i middleware | Logika biznesowa w złym miejscu |
| Logika biznesowa | Sprawdza reguły domenowe i decyduje, co wolno zrobić | Jasne use case’y i separacja odpowiedzialności | Mieszanie reguł z SQL-em albo frontendem |
| Dostęp do danych | Czyta i zapisuje dane w bazie lub w zewnętrznych systemach | Transakcje, indeksy, rozsądne zapytania | Nadmierne sprzężenie z strukturą tabel |
| Cache | Przyspiesza powtarzalne odczyty | Krótki czas życia i jasne zasady unieważniania | Cache jako fałszywe źródło prawdy |
| Kolejka i zadania w tle | Obsługuje rzeczy, które nie muszą kończyć się natychmiast | Retry, timeouty i idempotencja | Blokowanie odpowiedzi przez długie operacje |
| Uwierzytelnianie i autoryzacja | Sprawdza, kim jest użytkownik i co może zrobić | Uprawnienia na poziomie obiektu i funkcji | Przyznawanie dostępu tylko po stronie UI |
| Logi i monitoring | Pokazuje, co dzieje się w systemie i gdzie rosną błędy | Strukturalne logi, metryki, alerty | Brak danych, gdy coś się psuje |
REST, GraphQL, webhooki i gRPC nie służą do tego samego
Najwięcej nieporozumień widzę wtedy, gdy zespół wybiera styl API pod modę, a nie pod konkretny scenariusz. REST, GraphQL, webhooki i gRPC rozwiązują różne problemy, więc nie ma sensu pytać, które z nich jest lepsze w oderwaniu od kontekstu.
| Rozwiązanie | Kiedy się sprawdza | Największa zaleta | Najważniejsze ograniczenie |
|---|---|---|---|
| REST | Publiczne API, aplikacje mobilne, sklepy internetowe, klasyczne CRUD | Prosty model oparty na HTTP, łatwa dokumentacja, przewidywalność | Czasem wymaga kilku requestów do jednego widoku |
| GraphQL | Gdy frontend potrzebuje różnych zestawów danych z tych samych źródeł | Klient pobiera dokładnie to, czego potrzebuje | Trudniejszy cache, większa złożoność i nowe klasy błędów |
| Webhooki | Gdy system ma reagować na zdarzenia, na przykład płatność, wysyłkę lub zwrot | Dobrze wspierają komunikację asynchroniczną | Wymagają podpisywania, retry i kontroli duplikatów |
| gRPC | Komunikacja między usługami, szczególnie gdy liczy się wydajność | Szybki binarny protokół i mocny kontrakt | Trudniejszy do wdrożenia po stronie przeglądarki i partnerów zewnętrznych |
W większości sklepów i paneli administracyjnych REST plus webhooki wystarcza z dużym zapasem. GraphQL ma sens wtedy, gdy frontend potrzebuje wielu różnych widoków tych samych danych, a gRPC zostawiam zwykle do komunikacji między usługami, nie do publicznego API. Dokumentację warto spinać z kontraktem, na przykład w OpenAPI, czyli opisie endpointów, który da się czytać, testować i utrzymywać razem z kodem. Kiedy kontrakt API jest jasny, najwięcej ryzyk przenosi się do bezpieczeństwa i wydajności.
Bezpieczeństwo i wydajność, które najczęściej decydują o jakości
W API najdroższe są zwykle nie spektakularne exploity, tylko nudne błędy, które długo przechodzą niezauważone. OWASP nadal zwraca uwagę przede wszystkim na autoryzację na poziomie obiektu, błędną autoryzację funkcji, przeciążanie zasobów i SSRF, czyli sytuacje, w których serwer robi coś, czego nie powinien, albo robi to za dużo razy.
- Autoryzacja na poziomie obiektu - sam identyfikator w URL nie jest dowodem, że użytkownik może pobrać cudze zamówienie, fakturę albo adres.
- Uwierzytelnianie nie zastępuje autoryzacji - token mówi, kim jest użytkownik, ale dopiero reguły dostępu mówią, co wolno mu zrobić.
- CORS to nie zabezpieczenie API - kontroluje zachowanie przeglądarki, ale nie chroni samego endpointu.
- Ograniczanie liczby prób - logowanie, reset hasła i webhooki zewnętrzne wymagają twardych limitów; przy krytycznych akcjach stawiam na kilka prób w 10-15 minut, nie na dowolną liczbę.
- Walidacja i białe listy pól - chronią przed przypadkowym nadpisaniem danych, których frontend nie powinien w ogóle wysyłać.
- Zapytania parametryzowane - ORM pomaga, ale nie zwalnia z myślenia; wstrzyknięcia SQL nadal robią realną szkodę.
- Idempotentne operacje - przy płatności i zamówieniach to obowiązek, bo ponowione żądanie nie może tworzyć drugiego rekordu.
- Monitorowanie - patrzę na p95, błędy 4xx i 5xx oraz nietypowe skoki ruchu, nie tylko na średnią odpowiedzi.
Po stronie wydajności najczęściej wygrywają trzy rzeczy: paginacja na poziomie 20-50 rekordów, cache dla stabilnych danych na 60-300 sekund oraz kolejki dla zadań, które trwają dłużej niż 2-3 sekundy. Jeśli endpoint zaczyna zwracać setki kilobajtów albo miliony wierszy z bazy, najpierw ograniczam payload i dokładam indeksy, dopiero potem myślę o mocniejszej infrastrukturze.
Jeśli kontrakt jest jasny, ryzyka przesuwają się z samego API na to, jak system jest zbudowany i jak dowozi się zmiany. Właśnie dlatego wybór architektury ma tak duże znaczenie.
Monolit modularny czy mikroserwisy
W praktyce między monolitem a mikroserwisami nie wybiera się z zasady, tylko pod konkretny zespół, tempo zmian i liczbę domen. Modularny monolit zwykle jest lepszym startem, bo pozwala utrzymać transakcje, prostsze wdrożenia i krótszą ścieżkę debugowania.| Model | Kiedy ma sens | Plusy | Minusy |
|---|---|---|---|
| Modularny monolit | Mały lub średni zespół, jeden produkt, wspólne reguły biznesowe | Prostsze wdrożenia, łatwiejsze transakcje, szybsze debugowanie | Wymaga dyscypliny, żeby moduły nie zaczęły się mieszać |
| Mikroserwisy | Duży zespół, osobne domeny, realna potrzeba niezależnego skalowania | Autonomia zespołów, oddzielne wdrożenia, elastyczność organizacyjna | Tracing, sieć, wersjonowanie komunikatów i spójność danych są trudniejsze |
Mikroserwisy mają sens dopiero wtedy, gdy różne części systemu naprawdę żyją własnym życiem, mają osobne zespoły i wymagają niezależnego skalowania. W przeciwnym razie dokładamy sieć, opóźnienia, tracing, wersjonowanie komunikatów i problemy ze spójnością danych bez realnego zwrotu.
W sklepach internetowych, katalogach i panelach administracyjnych modularny monolit często wygrywa po prostu dlatego, że zamówienie, płatność i magazyn łatwiej utrzymać w jednym spójnym modelu. Gdy wybór architektury jest jasny, można bezpieczniej zaplanować sam proces dostarczenia.
Jak dowieźć backend bez przepalania budżetu i czasu
Najbezpieczniej budować backend pionowo, a nie szeroko. Najpierw jeden pełny przepływ, potem kolejne funkcje, bo wtedy szybciej wychodzą luki w logice, integracjach i uprawnieniach.
- Rozpisz scenariusze - zacznij od jednego krytycznego flow, na przykład produkt, koszyk, checkout, płatność i potwierdzenie zamówienia.
- Opisz kontrakt API - nawet prosty OpenAPI pomaga utrzymać spójność między frontendem, backendem i testami.
- Ustal model danych i reguły transakcji - zanim napiszesz kod, zdecyduj, które operacje muszą być atomowe, a które mogą być asynchroniczne.
- Zaimplementuj jeden przepływ end-to-end - pełna ścieżka lepiej pokazuje realne problemy niż dziesięć częściowych endpointów.
- Dodaj testy jednostkowe, integracyjne i kontraktowe - same testy jednostkowe nie wystarczą, jeśli integracje zewnętrzne mogą się wyłożyć.
- Włącz staging, monitoring i plan powrotu - jeśli trzeba ręcznie odtwarzać krok po kroku awarię, proces jeszcze nie jest gotowy do produkcji.
Przy operacjach, które trwają dłużej, warto zwracać 202 Accepted i oddawać wynik z kolejki, zamiast trzymać użytkownika na długim requestcie. Jeśli kroków nie da się odtworzyć bez ręcznej pomocy, to sygnał, że proces jeszcze nie nadaje się do produkcji. Właśnie na tym etapie różnica między „działa lokalnie” a „da się utrzymać w realnym ruchu” robi się najbardziej widoczna.
Co warto ustalić, zanim powstanie pierwsza linia kodu
Zanim zaczynam implementację, spisuję kilka odpowiedzi na kartce albo w specyfikacji. To nie jest formalność, tylko sposób na to, żeby backend nie rósł chaotycznie po pierwszych poprawkach i integracjach.
- Kto jest klientem API - frontend, aplikacja mobilna, partnerzy zewnętrzni czy tylko wewnętrzne usługi.
- Które operacje są krytyczne - logowanie, płatność, tworzenie zamówienia, zmiana stanu magazynu i generowanie dokumentów.
- Jak traktujesz błędy - kiedy zwracasz 4xx, kiedy 5xx i jak klient ma reagować.
- Jak wersjonujesz kontrakt - pełna zgodność wsteczna albo jasno oznaczone wersje, bez przypadkowych zmian łamiących integracje.
- Co ma się stać przy awarii zewnętrznej usługi - retry, timeout, kolejka, fallback albo ręczna interwencja.
- Gdzie trafiają logi i alerty - bez tego trudno odróżnić błąd użytkownika od awarii systemu.
Jeśli miałbym zostawić jedną praktyczną zasadę, to tę: w backendzie najbardziej opłaca się prostota tam, gdzie projekt jeszcze nie wymaga komplikacji. Dobrze opisany kontrakt, sensowna autoryzacja, paginacja, kolejki dla długich zadań i monitoring zwykle dają więcej niż modna architektura wybrana na starcie tylko dlatego, że dobrze brzmi.